
プラットフォームエンジニアリングと内部開発者プラットフォーム(IDP):統制を損なわずにチームを強化する
この5年間、クラウドネイティブなスタック、マイクロサービス、そしてAIワークロードで開発を進める多くの組織が、同じパターンに行き着いています。チームとインフラが速く拡大すればするほど、デリバリーは遅くなり、運用リスクは高まっていくのです。
チームはツールの乱立と設定のドリフトに疲弊します。セキュリティは事業を前に進めるどころか、後追いになりがちです。クラウドコストは売上の伸びを上回って増え続けます。そして「速く動く」ことから始まったはずが、いつの間にか「慎重に動く」に変わっていきます。なぜなら、本番環境への変更が予測不能に感じられるからです。
プラットフォームエンジニアリングと内部開発者プラットフォーム(IDP)は、この非対称性への解答として登場しました。各プロダクトチームに“小さなDevOpsチーム”になることを求めるのではなく、組織は社内開発者向けに「プロダクトとしてのプラットフォーム(platform-as-a-product)」を構築します。プラットフォームは、スピードと自律性を提供しながら、セキュリティ、標準、コストに関する厳格で透明性の高い統制を組み込みます。これらは、ゴールデンパス、ガードレール、ポリシー・アズ・コードによって強制されます。言い換えれば、チームはより速く動ける一方で、組織は“統制を失う”のではなく、より予測可能な統制を獲得するのです。
本記事では、クラウドプラットフォームエンジニアリングが何を解決するのか、そして本番運用に耐える内部開発者プラットフォームのアーキテクチャがどのようなものかを分解して解説します。さらに、デフォルトでのセキュリティとガバナンス、ゼロからMVPまでのロードマップ、そしてプラットフォームエンジニアリングを導入すべきタイミングについても取り上げます。
なぜプラットフォームエンジニアリングは開発者の現実的な痛みを解決するのか
バズワードを取り払って言えば、プラットフォームエンジニアリングは、スケールしたエンジニアリング組織がいずれ必ず直面する3つの問いに答えます:
- 運用リスクを増やさずに、どうすればデリバリーを加速できるのか?
- 本番環境を理解可能なまま保ちながら、開発者の認知負荷をどう下げるのか?
- セキュリティと標準を、手作業のチェックリストに依存せず、デフォルトにするにはどうすればいいのか?
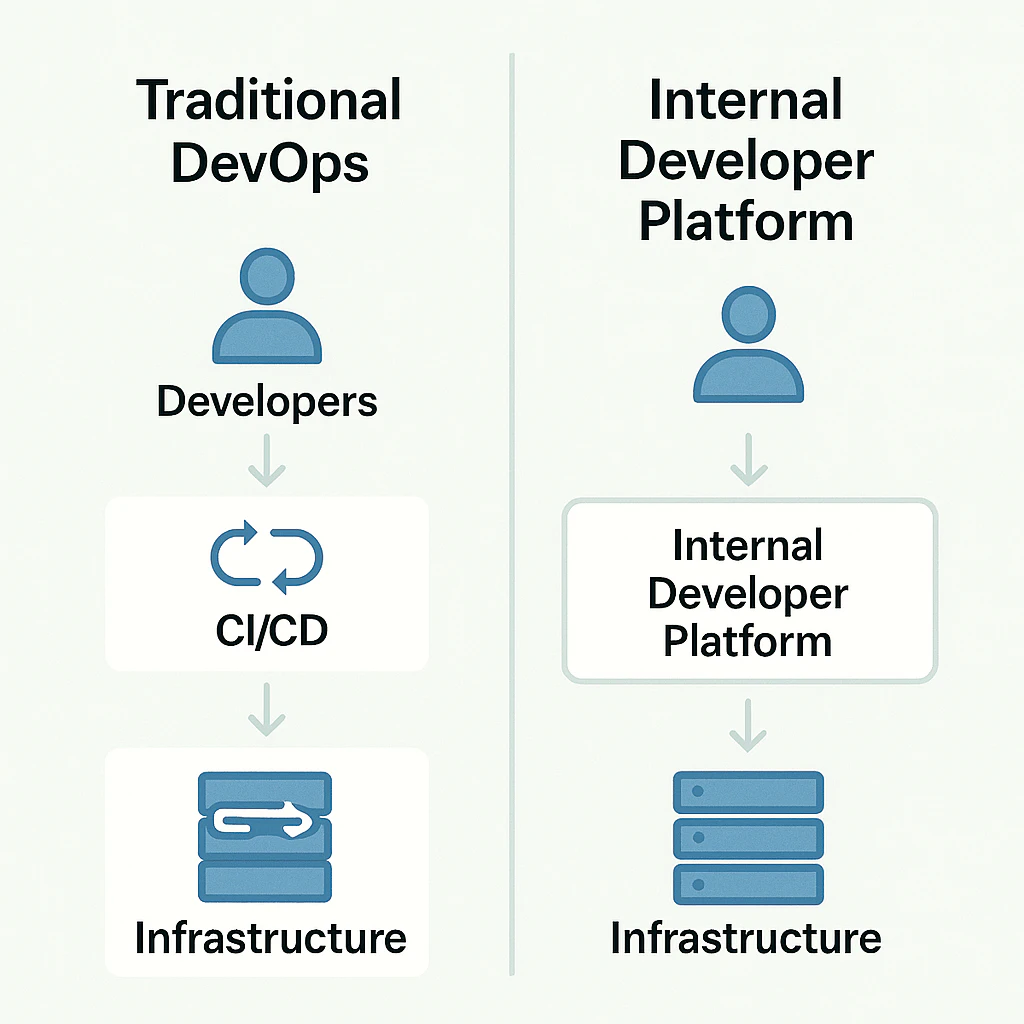
IDP導入前の典型的な組織は、だいたい次のような状態です:
- 何十(あるいは何百)ものサービスとリポジトリがあり、それぞれが独自のCI/CDの慣習、インフラのパターン、監視設定を持っている。
- オンボーディングに数週間かかる:エンジニアはクラスター、シークレット、パイプライン、フィーチャーフラグ、社内ツール、そして半分は古い複数のWikiを学ばなければならない。
- Ingressコントローラの移行やKubernetesのアップグレードのような全社横断の変更は、数え切れないほどのリポジトリに触れ、チーム間の調整が必要になるため、四半期単位の時間がかかる。
そして、予測可能な結果が現れる:
- テストカバレッジが十分でも、リードタイムは増加し、デプロイ頻度は低下する。
- シニアエンジニアは、機能ではなく「配線」に意味のある時間を割く:パイプライン、IAM、環境のトラブルシューティング、ダッシュボード、リリースの下回り。
- SREチームはインシデント疲労が蓄積する。ばらつきとドリフトが故障モードを増やし、インシデントはデバッグしづらくなる。
根本原因は「DevOps成熟度の不足」ではない。システムが、その場しのぎのプラクティスを超える規模に成長してしまったのだ。
その段階では、漸進的な修正は機能しなくなる。チーム間のばらつきを減らし、安全なデリバリーを反復可能にし、しかもすべての変更を調整プロジェクトにしない、耐久性のある運用レイヤーが必要になる。プラットフォームエンジニアリングは、プロダクトチームが依存できる共有の運用レイヤーで、一発ものの修正を置き換えることで、この3つの問いに答える。
クラウド・プラットフォームエンジニアリングがその痛みを減らす方法
クラウド・プラットフォームエンジニアリングは、プロダクトチームとインフラの間にプラットフォーム層を導入することで、これらの課題に体系的に対処します。ばらつきを減らし、パターンを標準化し、安全な道を最も簡単な道にします。
主な効果:
標準化されたデリバリーモデル
チームは、サービス、パイプライン、環境、オブザーバビリティのための「意図を持った」テンプレートを利用します。「各チームがそれぞれ作り方を発明する」のではなく、組織として一貫したデフォルトを用意して提供します。
高レベルのプリミティブによる認知負荷の低減
開発者は、低レベルの仕組みではなく、成果(アウトカム)ベースで作業します:
- 「新しいサービスを作成する。」
- 「プレビュー環境を立ち上げる。」
- 「機能を10%にロールアウトする。」
- 「デプロイの健全性とアラートを確認する。」
…「Helmをゼロから書く」や「IAMポリシーを手作業で作り込む」といった低レベル作業ではなく。
ガバナンスは「人」から「システム」へ移る
セキュリティ、ネットワークポリシー、コストコントロールは中央で定義され、自動的に強制されるようになります。これこそが、単なる「ツール導入」と、本当のプラットフォームエンジニアリングのソリューションを分けるポイントです。
プラットフォームエンジニアリングを導入すべき場合/すべきでない場合
プラットフォームエンジニアリングを導入する実践的なトリガー:
- 組織が成長し(チーム数・リポジトリ数が増え)、リリース速度が落ち始めた。
- 「作ったチームが運用も担う(You build it, you run it)」が、プロダクトチームに運用作業と割り込み対応の負荷を過剰に与えている。
- インフラとアーキテクチャが十分に複雑で、変更に数か月かかり、SREの深い関与が必要になっている。
- 規制領域(金融・医療)に入る、またはAIプロダクトをスケールしており、手作業のコンプライアンスではスケールしない。
これらのうち2〜3個に心当たりがあるなら、通常それが、プラットフォームエンジニアリングを戦略的に活用すべき最も明確なサインです。
まだプラットフォームエンジニアリングを導入しない方がよい場合:
- チームが1〜2で、デプロイ頻度も低い小規模な組織である。
- 主なボトルネックがデリバリー摩擦ではなく、プロダクトの方向性が不明確なことにある。
- 安定した土台(基本的なCI/CDの衛生、オーナーシップ、オンコール運用の規律)がまだ整っていない。
- プラットフォームを長期的なプロダクトとして資金投入し、所有する覚悟ができていない。
「なぜやるのか」が明確になったら、次に現実的な問いが出てきます:実際に何を作るのか? プラットフォームエンジニアリングは、プラットフォームが曖昧な「ポータル施策」ではなく、具体的な形を持つときにのみ機能します。そこで重要になるのが、明確で本番運用に耐えるIDPアーキテクチャです。
本番運用に耐えるIDPの全体像:コンポーネント、ゴールデンパス、ガードレール
本番運用に耐えるIDPは「ポータル」ではありません。一貫した開発者体験を提供し、標準を強制するための能力とワークフローの集合体です。
内部開発者プラットフォームのアーキテクチャを捉えるうえで役立つメンタルモデルは次の通りです:
- 体験レイヤー:ポータル/CLI/API、テンプレート、ワークフロー
- 制御レイヤー:ポリシー、アイデンティティ、ガバナンス、承認、ガードレール
- 実行レイヤー:コンピュート、ネットワーキング、CI/CD、環境
- テレメトリレイヤー:オブザーバビリティ、監査証跡、コスト可視化
この4つのレイヤーがシステムの形を表します。開発者のための体験、ガバナンスのための制御、デリバリーのための実行、そして学習と説明責任のためのテレメトリ。次のステップは、このモデルを、プラットフォームを使えるものにするために実際に実装すべき具体的なビルディングブロックへ落とし込むことです。
IDPの中核コンポーネント
以下は本番運用に必要な最小セットです。「最小」とは「簡単」という意味ではありません。「繰り返し可能で、サポート可能なデリバリーパスを作るために必要な最小限の能力セット」という意味です。
1. インフラのオーケストレーション
プラットフォームの役割は、インフラを隠すことではありません。インフラを、信頼できるセルフサービスの基盤へ変えることです。例外だらけの手作業を挟まずに環境を作れる、一貫した実行レイヤーと一貫した環境生成の仕組みが必要になります。
通常含まれるもの:
- コンピュート基盤:Kubernetes(最も一般的)、ECS、またはサーバーレス。ただし「明確なデフォルト」を1つ持つ。
- 宣言的プロビジョニング:インフラリソースにはTerraform/Pulumi。Kubernetesネイティブなリソース管理をしたい場合はCrossplane。
- 環境の抽象化:「dev」「staging」「prod」「preview」が、アカウント/クラスター/リージョンを跨いでも同じ意味になるように一貫した定義を持つ。
- 標準プラットフォームサービス:Ingress、DNS、証明書管理、シークレット連携、(任意で)サービスメッシュ、基礎ネットワーク。
- リソース境界:環境/チームごとのクォータと制限、加えて標準のラベリング/タグ付け。
環境ライフサイクル:環境を予測可能に作成・更新・ローテーション・破棄できること。
重要な理由:これによって「ペット環境(属人化した環境)」が排除され、「ステージングでは動くのに…」という類の問題が終わります。環境が一貫してセルフサービス化されると、チームはインフラ待ちなしでリリースでき、プラットフォーム全体の変更も、四半期単位の移行プロジェクトに化けにくくなります。
2. CI/CDとデリバリーのオーケストレーション
IDPにおけるCI/CDは「パイプラインのテンプレート」ではありません。品質とガバナンスをリリースフローに組み込んだ、標準化されたデリバリーメカニズムです。
通常含まれるもの:
- サービス種別(API/ワーカー/ジョブ/ML推論)向けの再利用可能なパイプライン構成要素
- 品質ゲート:テスト、(採用している場合)コードカバレッジの閾値、ビルド再現性
- セキュリティゲート:SAST、依存関係スキャン、コンテナスキャン、IaCスキャン
- アーティファクト管理:来歴(プロベナンス)メタデータ付きの、バージョン管理されたイメージ/パッケージ
- デプロイ戦略:カナリア、ブルー/グリーン、段階的デリバリー(リスクティアに紐づく選択肢)
- ロールバックの設計:自動ロールバックのトリガー+文書化された手動フォールバック手順
- GitOpsまたは宣言的な環境管理:Git上の望ましい状態、自动リコンシリエーション、監査可能な変更
- プロモーションモデル:コードをdevからstage、prodへどう進めるか、誰が昇格できるか、必要なチェックは何か
重要な理由:標準化されたデリバリーのオーケストレーションは、ばらつきを減らします。同時にガバナンスを左へ寄せます。後工程のレビューや例外対応ではなく、品質とセキュリティがすべてのリリースのデフォルト属性になります。
3. サービス/ソフトウェアカタログ
カタログは、本番環境に何が存在しているかを記録する「システム・オブ・レコード(信頼できる唯一の情報源)」です。これがないと、ガバナンス、インシデント対応、コスト配賦、プラットフォームの普及をスケールさせることはできません。
通常含まれるもの:
- サービスレジストリ:サービス名、リポジトリ、オーナー、ランタイム、環境
- 運用メタデータ:オンコールローテーション、SLO/SLA、重要度ティア
- 依存関係マッピング:上流/下流サービス、データストア、キュー、外部API
- コンプライアンス状況:PIIの取り扱い、データレジデンシー、暗号化要件、監査ログ要件
- ランタイム状況:最終デプロイ時刻、リリースバージョン、ヘルスチェック、アラート、ダッシュボードへのリンク
- AI資産(該当する場合):モデル、エンドポイント、データセット(少なくとも参照情報)、評価基準、モニタリングフック
重要な理由:カタログは、オーナーシップと影響範囲(ブラスト半径)を明確にします。これは、インシデント対応を速くし、プラットフォーム変更を安全に行うための土台です。また、ガバナンスを実行可能にします。ポリシーが、一般的なインフラルールだけではなく、「このサービスが何であるか」「どのデータに触れるか」を対象にできるようになるからです。
4. セルフサービス
セルフサービスは、プラットフォームの価値が開発者にとって現実になる地点です。「見た目が良いUI」ではありません。デリバリーの経路からチケットを取り除くことです。
通常含まれるもの:
- スキャフォールディングのワークフロー:テンプレートからサービスを作成(リポジトリ+設定+ポリシー)
- プロビジョニングのワークフロー:環境、データベース、キュー、キャッシュ
- アクセスのワークフロー:ポリシーに基づいて権限を申請(ロールベース+監査可能)
- 運用アクション:シークレットのローテーション、デプロイの実行、ロールバック、ステータス確認
- 標準的なDay-2タスク:スケーリング、設定変更、フィーチャーフラグ、プレビュー環境の作成
重要な理由:セルフサービスによって、プラットフォーム標準を日々の開発スピードに変換できます。日常的な作業が自動化され、ポリシーで裏付けられると、チームはSRE/インフラの順番待ちをしなくなり、プラットフォームチームも手作業の“依頼処理レイヤー”である必要がなくなります。
5. オブザーバビリティと運用ツール
IDPにおけるオブザーバビリティは、監視ツールを「入れてある」ことではありません。オブザーバビリティを、組み込み済みで標準化されたプラットフォーム機能にすることです。
通常含まれるもの:
- プラットフォーム注入のライブラリ/サイドカー/エージェントによる、ログ/メトリクス/トレースのデフォルト提供
- サービス種別ごとの標準ダッシュボード:レイテンシ、エラー率、飽和度、依存関係
- アラートの規約:オーナーへのルーティング、重大度定義、ページングルール
- SLOツール:エラーバジェット、バーンレート、リリースゲーティングルール
- ランブックのパターン:サービスごとに生成されるテンプレート、アラートからリンク
- 監査証跡:誰が何をデプロイしたか、どのポリシーがリリースをブロック/許可したか、設定ドリフトの履歴
- コスト可視化のフック:タグ、配賦レポート、異常検知アラート(ガバナンスと連動)
重要な理由:標準化されたテレメトリは、チーム間で共通の運用言語を作ります。これにより、デバッグ、オンコール、ガバナンスがサービスごとに“特注”になることがなくなります。また、リーダーシップにとっての制御ループも閉じられます。「ビルドが緑」だけではなく、変更を信頼性の結果やコストのシグナルに結び付けて追えるようになります。
次のステップは、チームが安全な道を再発明せずに繰り返せるようにすることです。その反復可能性こそが、ゴールデンパスが提供するものです。
ゴールデンパス:整備され、指針があり、サポートされる
ゴールデンパスとは、最も一般的で、かつ最も重要なエンジニアリングのシナリオに向けて事前に設計され、サポートされているワークフローです。
主な特性:
- 指針がある(オピニオネイテッド):推奨される道を1つに絞ることで意思決定の疲労を減らし、偶発的な複雑性を防ぐ。
- サポートされる:プラットフォームチームが保守し、監視し、進化させる。チームが放置されたテンプレートに取り残されることがない。
- 統合されている:その道にはすべてが含まれる。リポジトリのスキャフォールディング、CI/CD、セキュリティチェック、オブザーバビリティ、ロールアウト戦略。
例:新しいWebサービスのゴールデンパスでは、テンプレートからリポジトリを作成し、dev/stage環境をプロビジョニングし、SAST/DASTを接続し、ダッシュボードを設定し、安全なロールアウトを数分で有効化できる。
ゴールデンパスはデリバリーを標準化するだけではありません。行動を形づくります。整備された道が最速であれば、多くのチームは自然とそれに従います。とはいえ、本番運用は善意だけに依存できません。エッジケース、緊急修正、単発の要件は必ず発生します。プラットフォームには、「絶対に起きてはいけないこと」を明確にする境界が必要です。
ガードレール:壁ではなく縁石
ゴールデンパスは、推奨されるやり方を速くするためのものです。ガードレールは、プラットフォームを関所のような官僚組織にせずに、危険なやり方を難しくするためのものです。
重要な違いは「目的」です:
- ゴールデンパスはフローを最適化する:摩擦が少なく、高頻度の作業を速く回す。
- ガードレールは完全性を最適化する:稀だが高コストなミスを防ぐ。
成熟したIDPは、ガードレールで「譲れない不変条件」の小さな集合を守ります。セキュリティ姿勢、コンプライアンス統制、そしてユニットエコノミクスです。それ以外は柔軟性を保つべきです。
では、何がガードレールを「プラットフォーム品質(platform-grade)」にするのでしょうか? ガードレールがプラットフォーム品質である条件は次の通りです:
- 自動化されている — 人のチェックリストではなく、ポリシー・アズ・コードやパイプライン制御で強制される。
- 透明である — 開発者が何が失敗したのか、どう直せばよいのかを確認できる。
- リスクベースである — 重要度の高いサービスや規制対象データほど厳格になる。
- 滅多に邪魔をしない — 高摩擦の介入は日常的なブロッカーではなく、稀なイベントであるべき。
- 整備された代替案とセットである — 何かをブロックするなら、安全でサポートされた動く道を提供しなければならない。
ガードレールが日常のデリバリーを止めるようになると、チームは迂回します(シャドーツール、手動デプロイ、「一時的」な例外が恒久化)。
ガードレールはプラットフォームの完全性を守りますが、それ単体でスピードを生むわけではありません。スピードは、チームがインフラを意識せずに安全にリリースできる頻度から生まれます。だからこそ、ゴールデンパスとガードレールは必ずセットで提供されるべきです。片方は「正しいことを簡単に」し、もう片方は「間違ったことを難しく」します。
プラットフォームのDNAにセキュリティとガバナンスを組み込む
ゴールデンパスとガードレールはデリバリーを反復可能にしますが、反復可能であることだけで安全が保証されるわけではありません。プラットフォームが本番へのデフォルトルートになった瞬間、それは同時にリスクへのデフォルトルートにもなります。——セキュリティとガバナンスが、外部のチェックポイントではなく、プラットフォームのネイティブ機能として設計されていない限り。
これがクラウド・プラットフォームエンジニアリングの中核的な転換です。ガバナンスは、デリバリーの外側にある「別レーン」であることをやめ、デリバリーシステムそのものの一部になります。手動レビュー、暗黙知、後工程の承認に頼る代わりに、プラットフォームが標準を自動化としてコード化し、チームや監査人が信頼できる証跡(エビデンス)を生成します。こうして統制は、手作業のゲートの連続ではなく、デリバリーシステムのデフォルト属性になります。
コードとしてのガバナンス:ソフトウェアのようにリリースできるポリシー
ガバナンスをスケールさせるには、ソフトウェアのように振る舞わせる必要があります。バージョン管理され、テスト可能で、継続的に改善されることです。そうでなければ、ポリシーはPDFや「ベストプラクティス」に劣化し、チームは必ず迂回するようになります。
本番運用に耐える内部開発者プラットフォームのアーキテクチャでは、これは「ポリシーを仕事が行われる場所の近くへ寄せる」ことを意味します:
- インフラとランタイム(ネットワーク、暗号化、データ取り扱い、ワークロード制約)に対するポリシー・アズ・コード。
- サービスの重要度に基づくポリシーバンドル(Tier 0とTier 3の違いはラベルではなく、強制内容が変わる)。
- CIでのポリシーテストにより、変更を予測可能でレビュー可能にする。
- 厳格な例外フロー:明示的で、期限付きで、追跡可能。
ポリシーがコード化されれば、プラットフォームはそれを一貫して強制できます。しかし強制が機能するのは、プラットフォームが「誰が何をできるか」を、ポータル、CI/CD、クラウドアカウント、ランタイム環境にわたって制御できる場合だけです。だからこそ、アイデンティティとアクセスは、ツールごとの継ぎはぎではなく、プラットフォームの第一級の機能として設計されなければなりません。
アイデンティティとアクセス:プラットフォームは信頼できる唯一の情報源でなければならない
アイデンティティが分断されると、ガバナンスはスケール時に破綻します。ポータル、CI/CD、クラウドアカウント、クラスターがそれぞれ別々のアクセスモデルを持っていると、一貫した統制は実現できません。できるのは、継ぎはぎの修正と例外対応だけです。
だからこそ、成熟したプラットフォームエンジニアリングのソリューションは、アイデンティティをプラットフォームの第一級の関心事として扱います:
- SSO+RBAC/ABACを、プラットフォームのインターフェースと実行レイヤー全体に適用する。
- 最小権限をデフォルトにし、カタログ上のオーナーシップに紐づける。
- 期限付きで完全な監査ログを伴う、Just-in-timeの本番アクセス。
- 高リスク操作(IAM、キー、データエクスポート)に対する職務分離。
この段階で、アクセスは制御され、監査可能になり、オーナーシップと説明責任も明確になります。次に同じレベルで信頼できるようにすべきなのは、アーティファクトそのものです。何がビルドされ、何が含まれ、何が本番へ到達するのか。そこで、サプライチェーンセキュリティは「ベストプラクティス」から、プラットフォームに組み込まれた機能へと移行します。
サプライチェーンセキュリティ:何をリリースしたのかを証明する
クラウドネイティブシステムでは、最も高くつく失敗の原因は「悪いコード」であることは稀です。侵害された依存関係、追跡されていないイメージ、あるいは制御されていないビルドシステムから生まれます。だからこそ、アーティファクトの完全性は特例的な統制ではなく、標準のプラットフォーム機能でなければなりません。
そのためサプライチェーンセキュリティは、プラットフォームガバナンスの次のレイヤーになります:
- 署名付きアーティファクトと来歴(プロベナンス)メタデータ(コミット → ビルド → イメージ/パッケージ)。
- 依存関係/コンテナ/IaCスキャンを、標準のパイプラインゲートとして組み込む。
- SBOMの生成と保管(監査とインシデント対応のため)。
- 来歴を参照できるデプロイポリシー(「信頼された署名付きアーティファクトのみを本番にデプロイする」)。
何をリリースしたのかを証明できるようになれば、「なぜクラウドコストが増えたのか」という議論も減らせます。コストが、信頼性と同じように観測可能で、ガバナンス可能なものになるからです。
コストガバナンス:予算だけでなく、ユニットエコノミクスのためのガードレール
コスト管理がうまくいかないのは、それを財務レポーティングとして扱ってしまうときです。月次の請求書を見た時点では、エンジニアリング上の意思決定はすでに起きています——サービス単位、環境単位、そしてアーキテクチャ単位で。
デジタル・プラットフォームエンジニアリングのアプローチはこれを反転させます。コストはエンジニアリングのシグナルになり、健全な経済性がデフォルトの道になります。
- 強制されたタグ/ラベルと、オーナーシップに基づく配賦(カタログ由来)。
- 環境/チームごとのクォータと制限(サービスの重要度に整合)。
- サービス別・環境別のコストを、プラットフォームの体験レイヤーで可視化する。
- コストを意識したデフォルト(適正サイズのテンプレート、妥当なオートスケーリング、安全なストレージクラス)。
ここまでで、強制(ポリシー)、制御(アイデンティティ)、完全性(サプライチェーン)、経済性(コスト)が揃います。しかし、リーダーシップとコンプライアンスがまだ必要とするものがもう1つあります。エビデンス(証拠)です。
トラストループ:監査人とリーダーのためのエビデンス
これこそが、単発のツール導入と本当のプラットフォームエンジニアリングを分ける「ループを閉じる」ポイントです。ガバナンス対応のIDPは、無理な頑張り(ヒロイックな対応)なしに、次の問いへ答えられるようになります:
- 誰が、何を、いつ、そしてなぜデプロイしたのか?
- どのポリシーが、その変更を許可/ブロックしたのか?
- どの設定ドリフトが発生し、それはいつ起きたのか?
- SLOとコストのシグナルに、どんな影響が出たのか?
プラットフォームがこれらの答えを一貫して生成できるようになると、ガバナンスは摩擦ではなくなります。信頼性と信頼を増幅する仕組みになります。これは規制領域やAI比重の高いシステムにおけるプラットフォームエンジニアリングの約束そのものです。
ガバナンスがデフォルトとエビデンスとして実装されれば、デリバリーのブレーキではなくなります。しかし、それでも「チームが実際にリリースするやり方」にならなければ意味がありません。だからこそ、ロールアウトは小さくても完結したMVPから始めるべきです。代替手段より速く、設計上安全な、1本の整備された道(paved path)です。
ゼロからMVPへ:実践的な実装ロードマップ
最もよくある失敗は、IDPをビッグバンで一気に作ろうとすることです。しかし内部プラットフォームはプロダクトであり、プロダクトは早期に価値を届け、利用状況に基づいて拡張することで勝ちます。
したがって、内部開発者プラットフォームをどう作るかに対する最も実践的な答えはこうです:エンドツーエンドのゴールデンパスを1本リリースし、それを証明し、その後に増やしていく。
フェーズ0(2〜4週間):整合と制約の定義
作り始める前に、引き締まったスコープと測定可能な成果が必要です。そうでなければ、「プラットフォーム」がインフラに関するあらゆるものの受け皿になってしまいます。
このフェーズのアウトプットは、短いプラットフォーム・チャーターです:
- 顧客は誰か(どのチーム、どのワークロードか)?
- 最初のサービス種別は何か(Webサービス、ワーカー、ジョブ、MLエンドポイント)?
- 譲れない条件は何か(セキュリティ姿勢、環境モデル、オーナーシップのルール)?
- 主要なインターフェースは何か(ポータル vs CLI)?
そして何より重要なのは、成功指標を最初に定義することです:リードタイム、オンボーディング時間、デプロイ頻度、インシデント率。これらが、プラットフォームエンジニアリングを単なるツールのアップグレードではなく、戦略的投資として判断するためのベースラインになります。
これでMVPの準備が整いました。チケットを削減し、認知負荷を下げる、1つのワークフローです。
フェーズ1(4〜8週間):MVPのゴールデンパス
MVPはポータルではありません。反復可能で、サポートされたデリバリーループです:
- サービスをスキャフォールドする(リポジトリ、ベースライン設定、ポリシー)。
- 来歴(プロベナンス)付きでアーティファクトをビルドし、スキャンし、公開する。
- dev/stageへ一貫してデプロイする(GitOpsまたは同等の仕組み)。
- オブザーバビリティのデフォルト:ダッシュボード、アラートルーティング、ランブックへのリンク。
- オーナー/オンコール/重要度を含めてカタログに登録する。
ここから採用が始まります。チームが採用するのは「プラットフォーム戦略」ではなく、節約できた時間です。ゴールデンパスがリリースを実質的に楽にするなら、プラットフォームはブロッカーにならずに、より強いガードレールを追加するための“許可”を獲得できます。
フェーズ2(6〜12週間):ガードレールとDay-2運用
チームがプラットフォームで実際のワークロードを回し始めると、次のボトルネックはDay-2運用になります。日常的なアクションがまだSREチケットを必要とするなら、取り除こうとしたはずのキューを再び作ってしまいます。
そこでフェーズ2では、プラットフォームの運用面(オペレーショナルサーフェス)を拡張します:
- ランタイムとネットワーク制約のためのアドミッションポリシー。
- セルフサービスのロールバック、シークレットローテーション、プレビュー環境。
- 重要度に紐づく段階的デリバリー(Tier 0にはカナリア)。
- 期限付きの例外ワークフロー。
このフェーズの終わりには、プラットフォームは単なる「デプロイのやり方」ではなく、「スケールしても安全に運用するやり方」になります。
フェーズ3(継続):サービス種別を拡張し、ばらつきを減らす
ここからは、整備された道(paved paths)を増やしていくことでプラットフォームをスケールできます:
- より多くのサービス・アーキタイプを追加する(ワーカー、データパイプライン、ML推論)。
- すべての種別で、オブザーバビリティとガバナンスを標準化する。
- 全社横断の変更を安全にする(ベースイメージのアップグレード、ポリシー変更、ランタイムアップグレード)。プラットフォームが変更を予測可能にロールアウトできるようになるから。
この段階では、プラットフォームエンジニアリングがデフォルトの運用モデルになります。通常、組織がプラットフォームエンジニアリングの最も強いROIを感じるのはこのタイミングです。移行が四半期単位の調整作業ではなくなるからです。
プラットフォームがエンドツーエンドで機能し始めると、ボトルネックはエンジニアリングから行動へ移ります。一貫した利用、継続的な改善、そして効果の明確な証明が、「デリバリーをスケールさせるプラットフォーム」と「単なる任意のツール」で終わるプラットフォームを分ける要因になります。
導入、メトリクス、そしてプロダクト思考
どれほど優れた内部開発者プラットフォームのアーキテクチャであっても、それを「イネーブルメント用のツール」として扱うと失敗します。チームはリーダーシップに言われたから採用するのではありません。代替手段より明確に優れていて、しかも改善され続けるから採用します。
だからこそ、プラットフォームエンジニアリングにはプロダクト思考が必要です。明確な顧客、ロードマップ、サポート、そして測定可能な成果です。
プラットフォームエンジニアリングをプロダクトとして扱う
これはブランディングの話ではありません。説明責任を伴うサービスとしてプラットフォームを運用することです:
顧客セグメント(新規チーム vs 成熟チーム、規制対象 vs 非規制)。
- 社内の好みではなく、摩擦と利用状況に基づくロードマップ。
- UXとドキュメントを第一級の成果物として扱う。
- 社内SLAを備えたサポートモデル。
これによってプラットフォームは、プロダクトチームが日々依存できる、信頼性の高い社内プロダクトへと変わります。
価値を証明し(失敗もあぶり出す)メトリクス
導入を持続可能にするには、メトリクスが同時に2つの役割を果たす必要があります。第一に、プラットフォームがエンジニアの摩擦を減らしていること(スピードと認知負荷)を証明すること。第二に、組織としての統制が高まっていること(信頼性、セキュリティ姿勢、コスト規律)を証明することです。少数の指標を一貫して追跡し、ロールアウト前にベースラインを取り、たまの運用レポートではなくプロダクトKPIとしてレビューしてください。
実務では、メトリクスを「何を改善したいのか」と「何を守りたいのか」でグルーピングすると分かりやすくなります。以下のカテゴリは、プラットフォームの中核的な約束——より速いデリバリー、より安全な本番運用、より低い運用負荷、そして証明可能なガバナンス——に対応しています。
フロー
- 変更のリードタイム
- デプロイ頻度
- 初回デプロイまでの時間
- プレビュー環境の立ち上げにかかる時間
信頼性
- 変更失敗率
- MTTR(平均復旧時間)
- SLO遵守/エラーバジェット消費(バーン)
運用負荷
- シニアの時間のうち、パイプライン/IAM/環境トラブルシューティングに費やされる割合
- チームあたり・スプリントあたりのプラットフォーム関連チケット数
ガバナンスのエビデンス
- 本番前に検知されたポリシー違反
- 重大な脆弱性の修正までの時間
- サービス全体における署名付きアーティファクト/SBOMのカバレッジ
これらの数値が動かないなら、その“プラットフォーム”はプラットフォームではなく、新しい複雑性のレイヤーにすぎません。ですが、メトリクスがいくら良くても、利用が任意のまま、あるいは一貫しないままでは意味がありません。次のステップは導入を反復可能にすることです。チームが自分たちで作り直すのではなく、整備された道(paved paths)をデフォルトに選ぶようにするために。
実際に機能する導入戦略
導入はローンチではなく、ロールアウト戦略です:
- 痛みが強く、リファレンスケースになれるチームから始める。
- ゴールデンパスを最も簡単な道にする(目に見える時間短縮)。
- 逃げ道は残すが、明示的にする(期限付きの例外)。
- コミュニティのループを作る:オフィスアワー、フィードバック用チャネル、変更履歴(チェンジログ)。
これが、プラットフォームを「取り組み(initiative)」から社内標準へ変える方法であり、「なぜ/いつプラットフォームエンジニアリングを使うのか」という判断を、思想ではなく当たり前の選択として感じさせる方法です。
プラットフォームエンジニアリング実行のパートナーとして
Unique Technologiesは、プラットフォームエンジニアリングを「取り組み(initiative)」から本番システムへと変えることを、エンジニアリングリーダーと共に実現します。私たちは、測定可能な成果に基づく内部開発者プラットフォーム(IDP)アーキテクチャを設計・実装します。成果は、より速いデリバリー、より低い運用負荷、そしてクラウドネイティブおよびAIワークロードとともにスケールするガバナンスです。
私たちのアプローチは、実践的なクラウド・プラットフォームエンジニアリングの基盤(標準化された環境、CI/CDオーケストレーション、オブザーバビリティのデフォルト化)と、プラットフォーム品質の統制(ポリシー・アズ・コード、サプライチェーンの完全性、サービスのオーナーシップに紐づくコストガードレール)を組み合わせます。その結果、チームは摩擦が減るからこそプラットフォームを採用し、同時にリーダーシップはセキュリティ姿勢、信頼性、ユニットエコノミクスを明確に可視化できます。
プラットフォームエンジニアリングをいつ導入すべきか検討している場合でも、すでに構成要素はあるのに導入と一貫性に苦戦している場合でも、Unique Technologiesがお手伝いできます。ロードマップの定義から、MVPのゴールデンパスのリリース、そしてガバナンスを官僚化させることなく、社内プロダクトとしてプラットフォームエンジニアリングをスケールさせるところまで伴走します。