
イベント駆動アーキテクチャとサーバーレス:高負荷システムにおけるバックエンド再考
高負荷バックエンドシステムが破綻する理由は、単一のサービスが個別に不適切に実装されているからとは限りません。むしろ多くの場合、あまりにも多くのサービスが、同時に応答し、連携し、処理を完了することを強いられることで、徐々に安定性を失っていきます。同期型アーキテクチャは、トラフィックが予測しやすく、サービス間依存が限定的であれば、長い間うまく機能します。しかしスループットが増加し、統合が複雑化し、レイテンシ要件が厳しくなるにつれて、同じアーキテクチャが早期には見えにくいかたちで脆弱になっていきます。
こうした局面で、多くのチームはバックエンドをリクエスト・レスポンスの連鎖としてではなく、イベント、独立したリアクション、そして必要な場面にだけ割り当てられる計算資源から成るシステムとして捉え直し始めます。イベント駆動アーキテクチャは、サービス間の直接的な結合を減らし、トラフィックの急増をより穏やかに吸収し、よりスケーラブルな処理モデルを支えます。サーバーレスモデルはその柔軟性をさらに拡張し、イベントやリクエストが実際に発生したときにだけコードを実行することで、常にピーク負荷を想定したインフラを動かし続ける必要をなくします。
ただし、これらのアプローチが自動的に正解になるわけではありません。イベント駆動システムは、契約、可観測性、リトライ、一貫性をめぐる新たな複雑性を持ち込みます。サーバーレスコンピューティングアーキテクチャは、システムのある部分ではインフラ運用負荷を取り除く一方で、別の部分では新たなボトルネックやコストの歪みを生み出すことがあります。真の設計上の問いは、これらのモデルがモダンかどうかではありません。運用上の課題の形に合っているかどうかです。
本稿では、なぜ同期型の高負荷システムが負荷下で脆くなるのか、イベント駆動アーキテクチャがどこで実際の価値を生み、どこで新たなトレードオフをもたらすのかを検討します。また、非同期システムにおける可観測性、サーバーレス関数の実践的な限界、そしてこうした選択が日本を含むエンタープライズ環境にどう適用されるかについても掘り下げます。さらに、Unique Technologiesが実務において高負荷なイベント駆動システムをどのように設計しているかについても説明します。
同期型の高負荷システムが抱える本質的な問題
同期型の高負荷システムにおける本質的な弱点は、単なるレイテンシではありません。依存先のタイミングです。同期フローでは、あるサービスは別のサービスが「今この瞬間に」利用可能であり、許容可能な応答時間を保ち、現在の負荷に耐え、障害なく動作していることに依存します。下流のシステムが1つ遅くなるだけで、スレッド、コネクション、メモリ、リトライ、そしてユーザー向けリクエストがスタック全体で足止めされます。実際の高負荷環境では、これは単なるアプリケーションの問題ではなく、アーキテクチャ全体がトラフィック調整問題へと変わることを意味します。
これにより、いくつかの構造的制約が生じます。
- 時間的結合の強さ。 サービスが論理的には分離されていても、運用上は互いの応答時間に強く結び付いています。
- 障害の増幅。 局所的な遅延が、キューの滞留、タイムアウトの連鎖、リトライの洪水、そして上流でのユーザー体験の劣化へと波及します。
- スパイク耐性の低さ。 突発的なトラフィック増加は、オートスケーリングやキャッシュ戦略が追いつくより速く依存先を圧迫します。
- 非効率なリソース利用。 本来インラインで処理する必要のない作業が多く含まれていても、システムは最悪ケースの同期需要に備えて過剰にプロビジョニングされがちです。
このため、多くの高負荷システムは進化がますます難しくなります。チームは個々のコンポーネントを改善し続けますが、アーキテクチャそのものは依然として、あらゆる意味のある処理が即時かつ順番通りに実行されることを前提としています。
実際には、その仕事の多くはそもそもクリティカルパス上にある必要がありません。通知、監査ログ、検索インデックス作成、分析データの取り込み、下流システムとの同期、データエンリッチメント、各種バックグラウンドワークフローの多くは、非同期で処理できることが少なくありません。チームがその区別を明確に認識したとき、バックエンドは「本当に即時整合性が必要なもの」と「そうでないもの」を軸に再設計できるようになります。
この転換こそが、しばしばアーキテクチャのスケーラビリティに向けた最初の本質的な一歩になります。
イベント駆動アーキテクチャ:原則、パターン、そして裏目に出る場合
イベント駆動アーキテクチャは、バックエンドの通信モデルを変えます。ビジネスプロセスの各ステップでサービス同士が直接呼び出し合う代わりに、システムのある部分が意味のある出来事の発生をイベントとして発行し、他の部分がそれに独立して反応します。
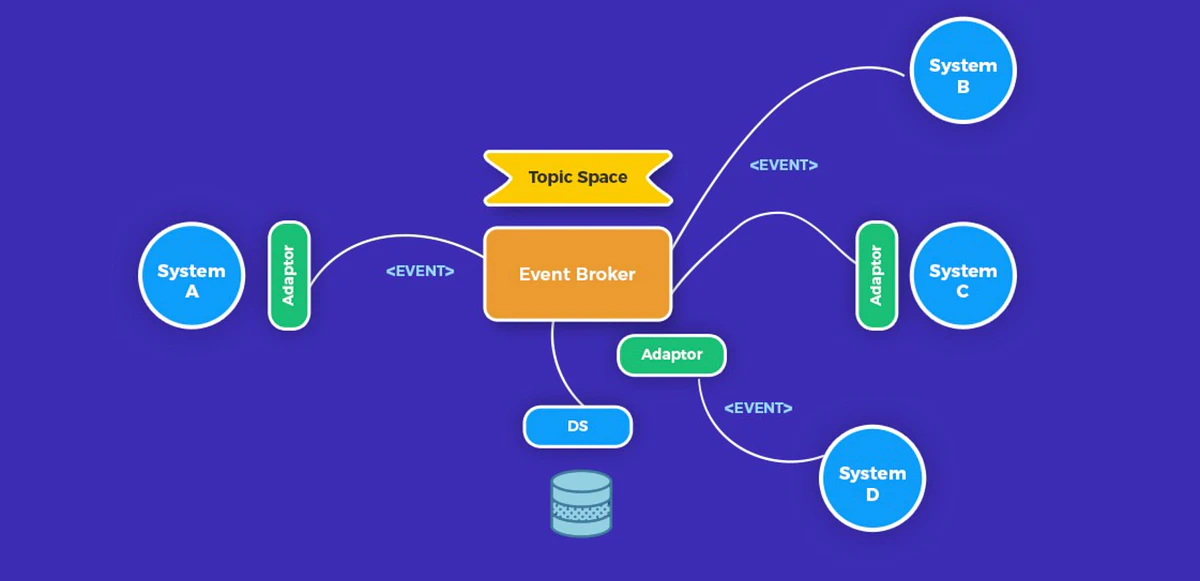
実務上、イベント駆動アーキテクチャの利点が本当に現れるのは、イベントが現実のドメイン上の振る舞いを適切に表現しており、かつシステムが曖昧な通知ではなく、厳格な契約に基づいて設計されている場合に限られます。
高負荷システムで有効な代表的パターンには、次のようなものがあります。
- イベント通知。 あるサービスが何かの変化を通知し、コンシューマー側が次のアクションを判断します。
- 状態を含むイベント伝達。 イベント自体にコンシューマーが必要とするデータを含めることで、追加の読み取りを減らし、発信元サービスへの負荷を下げます。
- Pub/Subによるファンアウト。 1つのイベントが、分析、通知、課金更新、コンプライアンス処理など、複数の下流アクションを引き起こします。
- トランザクショナル・アウトボックス。 状態変更と送信イベントを同一トランザクション内で永続化し、重要なメッセージが静かに失われることを防ぎます。
- Sagaベースのワークフロー。 分散されたビジネスプロセスを、失敗時の補償ロジックを伴う一連のステップとしてモデル化します。
これらのパターンは、システムが以下のいずれか、または複数を必要とする場合に特に有効です。
- 不規則なトラフィックを吸収する
- 独立したコンシューマー群に作業を分散する
- 顧客向けリクエスト経路から副作用を切り離す
- レガシーとモダンなサービスを、深いポイントツーポイント依存なしに統合する
- 本質的に非同期なドメインワークフローを処理する
このとき、イベント駆動アーキテクチャの利点は具体的な形を取ります。チームは通常、次のような成果を得ます。
- バースト負荷下での耐障害性向上
- ワークロードの分離の明確化
- より柔軟なスケーリング
- プロデューサーとコンシューマー間の結合低減
- 複数の社内外システムを現実的に統合するための手段
一方で、イベント駆動アーキテクチャは予測可能な形で裏目に出ることもあります。
典型的に問題が起きるのは、チームが次のようなことをした場合です。
- 不安定なイベントペイロードを公開し、それを長期的契約ではなく実装詳細として扱う
- 単純な同期呼び出しの方が容易かつ安全だった場面にまで非同期メッセージングを導入する
- 明示的な制御や説明責任が必要なワークフローに対しても、あらゆる場面でコレオグラフィに依存する
- 重複配信、リトライ、冪等性、デッドレターハンドリングを軽視する
- 「疎結合」を「理解しやすい」と取り違える
ここで多くのチームが遅れて気付くのは、EDAは複雑性を消し去るのではなく、再配置するだけだということです。
適切に設計されたイベント駆動システムは、確かにスケールしやすくなります。しかし最もよくある失敗パターンは、スケーラビリティのためにEDAを採用したチームが、その後6か月をかけて、8本のキューにまたがるビジネスプロセスをデバッグすることになるケースです。相関IDもなく、デッドレターの可視性もなく、運用担当者が注文の現在地を把握する術もありません。
イベント駆動システムにおける可観測性の課題
システムが非同期化した瞬間、可観測性はサービス単位の課題ではなく、フロー単位の規律になります。
同期型アーキテクチャでは、エンジニアは通常、1つのリクエストを一定範囲の実行パスの中で追跡できます。イベント駆動システムでは、同じビジネス上のアクションが、複数のメッセージ、リトライ、遅延したコンシューマー、並列ハンドラー、そして異なる場所と時間で生じる下流効果へと分解されます。
これによって、多くのチームが過小評価する可視性の問題が生まれます。
本番環境で本当に重要になるのは、あるコンシューマーが健全か、あるキューに到達可能か、といった純粋に技術的な問いだけではありません。より運用・業務寄りの問いになります。
- この注文、支払い、ドキュメント、ワークフローは、今どこにあるのか
- どのコンシューマーが進行を遅らせているのか
- バックログの増加はプロデューサー側の量なのか、コンシューマー障害なのか、それとも下流の遅延なのか
- リトライは復旧に寄与しているのか、それとも不安定性を増幅しているのか
- どのイベントバージョンがサービス間の破綻を引き起こしているのか
こうした問いに答えるために、高負荷のイベント駆動システムには、標準的なログやインフラダッシュボード以上のものが必要です。
- イベント全体を通して伝搬する相関IDと因果関係ID
- 安定したイベントスキーマとバージョニング規則
- 非同期境界をまたぐ分散トレーシング
- キュー深度とコンシューマー遅延の監視
- デッドレターキューの可視性
- イベントの経過時間と処理レイテンシのメトリクス
- サービスダッシュボードだけでなく、ビジネスフローダッシュボード
ここで多くのチームは高くつく誤りを犯します。スケーラビリティのために非同期アーキテクチャを構築しながら、可観測性をCPU、メモリ、アプリケーションログのレベルに留めてしまうのです。その結果、大量の処理を技術的にはこなせるものの、ビジネス上の仕事がどこで詰まっているのかを説明できないシステムが生まれます。
エンタープライズプラットフォームにとって、それでは不十分です。高負荷アーキテクチャは、負荷に耐えるだけでなく、負荷下でも診断可能でなければなりません。だからこそ、イベント駆動システムにおける可観測性は、後から運用上の応急処置として足すものではなく、アーキテクチャの一部として設計される必要があります。
ただし、可視性があるだけでは非同期システムは運用上健全にはなりません。チームがシステム内での仕事の流れを見えるようにした後、次に問うべきは、その仕事を変動する負荷の中でどのように実行すべきかです。つまり、議論は通信パターンから実行モデルへと移ります。ここでサーバーレスが登場します。
サーバーレスが有効な場面と、静かに最大の問題へと化す場面
サーバーレスコンピューティングアーキテクチャは、疎結合の原則をさらに一歩進めます。サーバーを事前に用意する代わりに、オンデマンドで実行され、アイドル時にはゼロまでスケールし、負荷に応じて自動的にスケールアウトする関数をデプロイします。キュー、ストリーム、オブジェクトストレージ、データベースといったマネージドなイベントソースと組み合わせれば、プラットフォームチームからインフラ運用の一大カテゴリを丸ごと取り除くことができます。
適切なワークロードに対しては、これは大きな変革です。しかし不適切なワークロードでは、サーバーレスが静かにシステム最大の運用問題になります。
サーバーレス関数が真価を発揮する場面
- 変動負荷のイベント処理。 ワークロードがバースト的または予測しにくい場合、たとえばWebhookの取り込み、画像処理、ストリーム変換、定期ジョブなどでは、サーバーレスは手動スケーリングやアイドルコストなしに需要へ容量を合わせられます。
- マネージドサービス間のグルーコード。 オブジェクトストレージへのアップロードに反応し、ファイルを変換してデータベースに書き込むような小さな関数は、まさにサーバーレスが得意とする領域です。
- スパイクのある低〜中程度スループットのAPI。 サーバーレスは、事前の容量計画なしにトラフィックスパイクを吸収できます。24時間365日高負荷で動き続けないバックエンドにとって、経済性と運用のシンプルさは非常に魅力的です。
- 境界が明確な独立ワークロード。 関数が1つの仕事、1つの入力ソース、1つの出力先を持つとき、サーバーレスは1人のエンジニアがエンドツーエンドで責任を持ちやすくします。
サーバーレスが静かに最大の問題になる場面
- 高スループットでレイテンシに敏感なAPI。 コールドスタート、同時実行数制限、呼び出しごとのオーバーヘッドはすぐに積み上がります。コールドスタート自体は対処可能な場合も多いものの、標準的な対策であるProvisioned Concurrencyは、一定数の関数インスタンスを事前初期化したまま維持し、トラフィックにかかわらず継続的に課金されます。これは「使った分だけ支払う」モデルを、事実上、予約済み容量モデルに近いものへ変えてしまいます。本来サーバーレスが置き換えるはずだったモデルそのものです。関数が24時間高頻度で稼働するような持続的高スループット環境では、実行時間が数百ミリ秒を超えたり、ウォームキャッシュがレイテンシに大きく効いたりすると、サーバーレスの呼び出し単価モデルは、適正サイズのコンテナ群より高くつくのが一般的です。
- 長時間実行ワークロード。 多くのサーバーレスプラットフォームには実行時間上限があります。ジョブが恒常的にその上限を超えるなら、チームは本来の課題を解く代わりに、その制限を回避する設計に追い込まれます。
- 重いローカル状態やウォームキャッシュを必要とするワークロード。 コールドスタートのたびに環境は初期状態に戻ります。インメモリキャッシュ、ロード済みのMLモデル、持続的コネクションの恩恵を受ける関数は、呼び出しのたびに税金のようなコストを払うことになります。
- 従来型データベースとの深い統合。 コネクションプーリングはよく知られた難所です。何百もの並列関数インスタンスがリレーショナルデータベースへ接続を開けば、関数プラットフォームの限界に達する前にプールが枯渇します。
- 複雑なローカル開発とテスト。 サーバーレスプラットフォームはクラウドごとの差異が大きく、ローカルでの同等性は限定的です。統合テストは難しく、「コンソールでは動く」は信頼できるシグナルになりません。失敗のパターンは一貫しています。チームはインフラ作業をなくせるという期待からサーバーレスを採用するものの、その制約を回避するために何か月も費やし、最終的にはインフラそのものより高くつく形になります。サーバーレスは、ワークロードがそのモデルに合致するときには成果を出す特化型ツールであり、合わない場合には不適切な選択になります。
この整理が重要なのは、サーバーレスの最も強力なユースケースが「APIをそれで動かすこと」ではないからです。真価は、イベント駆動アーキテクチャと組み合わせ、弾力的で非同期な実行がまさに必要なワークロードに適用することにあります。
EDAとサーバーレスの組み合わせ:高負荷システム向けアーキテクチャパターン
最も効果的なシステムは、多くの場合、イベント駆動アーキテクチャとサーバーレスを同一視するのではなく、EDAに選択的なサーバーレス利用を組み合わせています。
EDAはシステム各部がどのように通信するかを定義します。サーバーレスは、その仕事の一部を実行する1つの方法を定義します。両者を慎重に組み合わせれば、スケーラブルでありながら運用効率にも優れたアーキテクチャを実現できます。
高負荷システムで特に有効なパターンはいくつかあります。
1. 非同期インバウンド
リクエストがシステムに入り、基本的な検証は即座に行い、コアとなる意図を記録します。同期的に処理する必要のないものはすべてイベントとして発行し、下流で処理します。
このパターンは次のような場合に有効です。
- ユーザー向けフローを高速に保ちたい
- 下流処理の所要時間が一定でない
- サードパーティ依存先の信頼性が低い
- 1つのアクションが複数の後続処理を引き起こす
2. Outbox + Fan-Out Consumer
あるサービスがビジネス上の変更を永続化し、同じトランザクション内で送信イベントも記録します。そのイベントは公開され、プラットフォームの他の部分で独立して消費されます。
これは次のような場面で有効です。
- 注文処理
- 課金イベント
- 通知システム
- 監査およびコンプライアンスパイプライン
- 検索および分析更新
3. オーケストレーションされたクロスサービス・ワークフロー
暗黙的なコレオグラフィだけに任せるには重要すぎるワークフローもあります。その場合、コーディネーターやワークフローエンジンが、より明確な運用モデルを提供します。
これは次のような場合により適しています。
- 複数のサービスが1つのビジネスプロセスを完了する必要がある
- 補償アクションが必要である
- ワークフロー状態を運用担当者が可視化できる必要がある
- チームがより明確なガバナンスと監査性を必要としている
4. エッジではサーバーレス、コアでは永続的サービス
これはエンタープライズシステムにとって最も実践的なパターンであることが多いです。
サーバーレス関数を使う領域:
- インバウンドイベント
- 外部システム連携
- ファイル起点の処理
- トラフィックバースト
- 軽量な変換処理
永続的なサービスやコンテナを使う領域:
- 状態を持つビジネスロジック
- 長時間実行タスク
- レイテンシに敏感なAPI
- 複雑なワークフロー制御
- コアドメイン処理
このハイブリッドモデルにより、チームはイベント駆動アーキテクチャとサーバーレスソリューションの利点を多く享受しながらも、プラットフォーム全体を単一の運用スタイルに押し込める必要がなくなります。
このバランスこそが、拡張可能なシステムと、流行に引っ張られただけのアーキテクチャとを分けるものです。とりわけ日本のエンタープライズ文脈では、この違いが重要になります。なぜなら、そこでのアーキテクチャ選定は性能目標だけでなく、予測可能性、保守性、そして統制されたモダナイゼーションの要求にも左右されるからです。
日本のエンタープライズ環境におけるEDAの適用
2025年から2026年にかけて、日本企業は特有の制約の組み合わせに直面しています。多くの企業は、15年から20年にわたり本番運用されてきたシステムのモダナイゼーションに取り組んでいますが、その環境は長期的なベンダー関係、厳格な運用期待、そして監査性・予測可能性・相互運用性への強い要求によって形作られています。その一方で、モバイルアプリケーション、リアルタイムのデジタルサービス、AI搭載機能といった消費者向けプロダクトは、多くのレガシーバックエンドがもともと想定していなかったレベルの弾力性と応答性を求めています。
この緊張関係こそが、イベント駆動アーキテクチャが日本企業の現実に、第一印象以上に自然に適合する理由の1つです。経済産業省(METI)が近年示しているレガシー刷新の方向性は、硬直化し老朽化したシステム群から、継続的なビジネス変化を支えられるアーキテクチャへ移行する必要性を反映しています。同時に、デジタル庁はシステム間の相互運用性、共通ルール、構造化データ交換を重視しています。これらの優先事項を総合すると、不透明なポイントツーポイント結合よりも、明示的な契約、追跡可能なシステム挙動、管理しやすい統合モデルが好まれることになります。
この緊張関係こそが、イベント駆動アーキテクチャが日本企業の現実に、第一印象以上に自然に適合する理由の1つです。経済産業省(METI)が近年示しているレガシー刷新の方向性は、硬直化し老朽化したシステム群から、継続的なビジネス変化を支えられるアーキテクチャへ移行する必要性を反映しています。同時に、デジタル庁はシステム間の相互運用性、共通ルール、構造化データ交換を重視しています。これらの優先事項を総合すると、不透明なポイントツーポイント結合よりも、明示的な契約、追跡可能なシステム挙動、管理しやすい統合モデルが好まれることになります。
実務上、この環境でEDAが最も効果を発揮するのは、オールオアナッシングのアーキテクチャスタイルとしてではなく、統制されたモダナイゼーションのための境界戦略としてです。特に、レガシーコアと新しいデジタルチャネルの境界、異なるベンダーが所有するシステムの境界、そしてコア取引基盤と下流の分析、通知、コンプライアンスワークロードの境界で大きな価値を発揮します。
このアプローチが日本で特に有効である理由は、いくつかあります。
1. 監査性はイベントストリームの本質的な特性である
日本の規制産業、たとえば金融、医療、保険、通信では、状態変化の追跡可能な記録が求められます。イベントソーシングまたはイベントログ型のシステムは、そのような記録を運用の副産物として自然に生み出します。すべての状態遷移が、永続化され、タイムスタンプ付きで、再生可能なイベントになるからです。「誰が、何を、いつ、なぜ変更したか」がコンプライアンス要件である組織にとって、EDAは新しいパターンというより、既存の期待を形式化したものと言えます。
2. リライトリスクを伴わない段階的モダナイゼーション
日本企業は通常、ビッグバン移行を許容できません。イベント駆動パターンは、ストラングラーパターン型のモダナイゼーションを支えます。レガシーシステムは引き続き同期トランザクションを処理しつつ、そこから発行されるイベントが、新しい機能、たとえばAI推論、リアルタイム分析、モバイル機能へと流れ込みます。レガシーコアを大きく変えずに、新しいシステムを並行進化させられるのです。
3. 日本の運用文化に適合するレジリエンス
日本のエンジニアリング文化は、予測可能な運用と明確なエスカレーション経路を重視します。EDAを適切に実装すれば、まさにそれが得られます。障害は個別のコンシューマーに局所化され、リトライは明示的で、デッドレターキューは可視化され、復旧手順は定義されます。これは、分散システムに対する不信感を生みやすい「原因不明の障害」とは正反対です。
4. 運用負荷に対するヘッジとしてのサーバーレス
エンジニア人員が限られている日本企業、特に多くの中堅企業にとって、サーバーレスソリューションはクラウドプロバイダーへ運用負荷の大きな部分を委ねられる手段です。スケーリング、パッチ適用、容量計画、アイドルリソース管理は社内の懸念事項ではなくなります。これは、システムの志向に対してエンジニアリングチームが小規模である場合、極めて大きな意味を持ちます。
5. 明示的なスキーマ契約による相互運用性
デジタル庁のフレームワークは、システムが定義された安定的なインターフェースを通じてデータを公開・取得することを求めています。EDAはまさにそれを強制します。すべてのイベントが、バージョン管理され、スキーマで統治されたプロデューサーとコンシューマー間の契約になるからです。スキーマレジストリを備えたイベント駆動アーキテクチャは、単なるスケーラビリティ上の選択ではなく、相互運用性要件に対する構造的な適合でもあります。安定したスキーマを通じてイベントを交換するシステムは、インターフェースを作り直すことなく、独立して統合、監査、置換できます。
注意点として、EDAとサーバーレスはどちらも導入時の規律を必要とします。スキーマ管理、可観測性、明確なイベントオーナーシップは、スケールが到来した後ではなく、その前に整備しておく必要があります。日本企業は、こうしたアーキテクチャ選択を意図的に行う場合にはこれをうまく実践する傾向がありますが、運用基盤を整えないまま海外の参照アーキテクチャを模倣してEDAを導入すると苦労しがちです。
Unique Technologiesはイベント駆動システムをどう構築するか
Unique Technologiesでは、イベント駆動およびサーバーレスコンピューティングアーキテクチャが、本番環境で測定可能な成果を生み出すよう、エンジニアリングリーダーとともにバックエンドシステムの設計・運用を支援しています。私たちの取り組みは、3つの原則を中心に据えています。
1. アーキテクチャの意思決定は流行ではなく制約から始める
私たちはあらゆるプロジェクトで、実際のワークロードをまずマッピングします。スループットのパターン、レイテンシ要件、障害モード、チーム成熟度、コンプライアンス制約を把握します。イベント駆動アーキテクチャのパターンは、ファンアウト負荷、下流障害下での耐障害性、監査性、非同期処理の弾力的スケーリングといった、特定の問題を解く場合に導入します。実務上、私たちがレビューする統合の約半分はメッセージブローカーを必要としません。必要なのは、サーキットブレーカーと適切なタイムアウト処理を備えた、より良い同期設計です。残りの半分は、実際に同期結合がボトルネックになっており、イベント駆動パターンの恩恵をすぐに受けられます。アーキテクチャにコミットする前に、その見極めを行うことに最も大きな価値があります。目標はパターンへの忠実さではなく、適合性です。
2. 可観測性とガバナンスを最初から組み込む
私たちは、スキーマレジストリ、相関ID、分散トレーシング、デッドレターキューの責任分担、ビジネスレベルのダッシュボードを、初日からの成果物として扱います。私たちの設計したシステムを引き継ぐチームは、プレッシャーのかかる状況でもデバッグできます。なぜなら、可観測性レイヤーが後付けではないからです。サーバーレスソリューションについても、本番トラフィック到来前に、ローカル開発の同等性、統合テスト、コスト可視性をプラットフォームへ組み込みます。
3. ビジネスを止めずに移行を進める
私たちのエンタープライズ顧客の多くは、新規にゼロから作るのではなく、既存システムを進化させています。そのため、EDAやサーバーレス関数をレガシーシステムと並行して導入する際には、全面置換ではなく、ストラングラーパターン、デュアルライト移行、イベントログブリッジを用います。レガシーコアは動き続け、その横で新しい機能が立ち上がります。旧経路は新経路が十分に実証されるまで取り除かれないため、常にロールバック可能です。
Unique Technologiesは、その違いを実務レベルで見極める支援を行います。私たちは、高負荷システムを安全にスケールさせるために必要なアーキテクチャ、可観測性、統合戦略を備えた設計と進化を提供します。イベント駆動アーキテクチャやサーバーレスコンピューティングアーキテクチャが高負荷バックエンドにとって適切な答えかどうかを評価している場合も、すでに取り組みを始めていて、本番環境でこうしたシステムを構築してきたパートナーを必要としている場合も、Unique Technologiesは、厳密な判断とビジネスを止めない実行の両面で支援できます。