
Platform Engineering and Internal Developer Platforms: Empowering Teams Without Sacrificing Control
Over the last five years, most organizations building with cloud-native stacks, microservices, and AI workloads have discovered the same pattern: the faster teams and infrastructure grow, the slower delivery becomes, and the higher operational risk climbs.
Teams get overwhelmed by tool sprawl and configuration drift. Security trails the business instead of enabling it. Cloud spend increases faster than revenue. And what started as “moving fast” slowly turns into “moving carefully,” because production changes feel unpredictable.
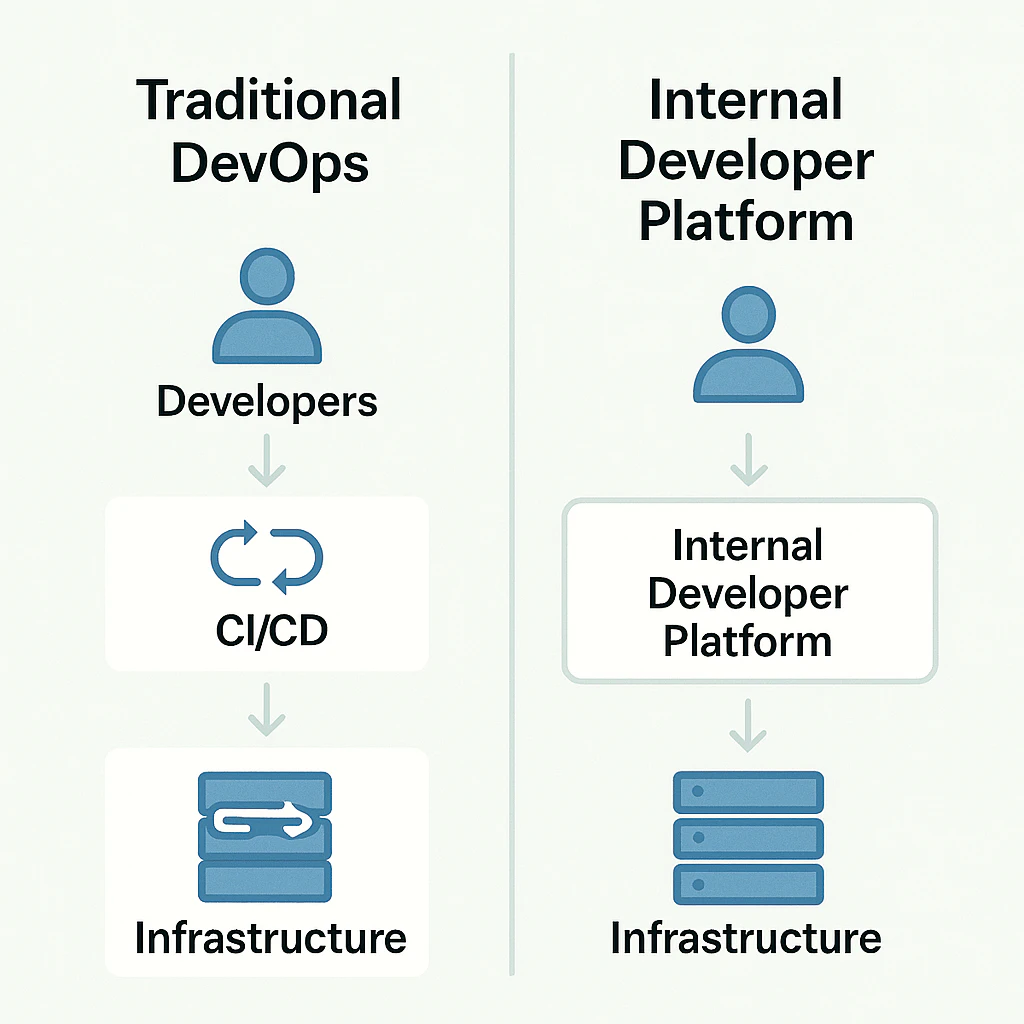
Platform engineering and Internal Developer Platforms (IDPs) emerged as a response to that asymmetry. Instead of teaching every product squad to become a mini-DevOps team, organizations build a platform-as-a-product for internal developers. The platform combines speed and autonomy with strict, transparent controls around security, standards, and costs, enforced through golden paths, guardrails, and policy-as-code. In other words, teams move faster while the organization gains more predictable control, not less.
In this article, we’ll break down what cloud platform engineering solves and what a production-grade internal developer platform architecture looks like. We’ll also cover security and governance by default, a zero-to-MVP roadmap, and when to adopt platform engineering.
Why Platform Engineering Solves Real Developer Pain?
Strip away the buzzwords, and platform engineering answers three questions every scaled engineering org eventually faces:
- How do we accelerate delivery without increasing operational risk?
- How do we reduce developer cognitive load while keeping production understandable?
- How do we make security and standards default, not dependent on manual checklists?
A typical organization, before an IDP, looks like this:
- Dozens (or hundreds) of services and repositories, each with its own CI/CD conventions, infrastructure patterns, and monitoring setup.
- Onboarding takes weeks: engineers must learn clusters, secrets, pipelines, feature flags, internal tooling, and multiple wikis that are half-outdated.
- Cross-org changes like migrating an ingress controller or upgrading Kubernetes take quarters because they touch countless repos and require coordination across teams.
Then the predictable consequences show up:
- Lead time increases and deployment frequency drops, even with solid test coverage.
- Senior engineers spend a meaningful share of time on “wires” instead of features: pipelines, IAM, environment troubleshooting, dashboards, and release plumbing.
- SRE teams accumulate incident fatigue because variability and drift create more failure modes and harder-to-debug incidents.
The root cause isn’t “lack of DevOps maturity.” It’s that the system has outgrown ad-hoc practices.
At that point, incremental fixes stop working. You need a durable operating layer that reduces variability across teams and makes safe delivery repeatable, without turning every change into a coordination project. Platform engineering answers those three questions by replacing one‑off fixes with a shared operating layer that product teams can rely on.
How Сloud Platform Engineering Reduces That Pain?
Cloud platform engineering systematically addresses these issues by introducing a platform layer between product teams and infrastructure, reducing variability, standardizing patterns, and making the safe path the easiest one.
Key effects:
1. Standardized Delivery Models
Teams use opinionated templates for services, pipelines, environments, and observability. Instead of “every team invents its own,” the organization ships with consistent defaults.
2. Reduced Cognitive Load Through Higher-Level Primitives
Developers operate in terms of outcomes:
- “Create a new service.”
- “Spin up a preview environment.”
- “Roll out a feature to 10%.”
- “Check deployment health and alerts.”
…not low-level mechanics like “write Helm from scratch” or “manually craft IAM policies.”
3. Governance Moves From People to Systems
Security, network policies, and cost controls become centrally defined and automatically enforced. That’s what separates “tooling” from real platform engineering solutions.
When to Adopt Platform Engineering and When Not to
Practical triggers for when to adopt platform engineering:
- Your org grew (more teams, more repos), and release velocity started falling.
- “You build it, you run it” overloaded product teams with operational work and interruptions.
- Infrastructure and architecture are complex enough that changes take months and require heavy SRE involvement.
- You’re entering regulated domains (finance, health) or scaling AI products, and manual compliance doesn’t scale.
If you recognize yourself in 2-3 of these, that’s typically the clearest sign of when to use platform engineering strategically.
When not to adopt platform engineering (yet):
- You’re a small org with 1-2 teams and low deployment frequency.
- Your main bottleneck is unclear product direction, not delivery friction.
- You don’t have stable foundations (basic CI/CD hygiene, ownership, on-call discipline).
- You’re not ready to fund/own a platform as a long-term product.
Once the “why” is clear, the next question becomes practical: what are you actually building? Platform engineering only works if the platform has a concrete shape, not a vague “portal initiative.” That’s where having a clear, production-grade IDP architecture matters.
Anatomy of a Production-Grade IDP: Components, Golden Paths, and Guardrails
A production-grade IDP is not “a portal.” It’s a set of capabilities and workflows that collectively deliver a consistent developer experience and enforce standards.
A useful mental model for an internal developer platform architecture is:
- Experience layer: portal/CLI/APIs, templates, workflows
- Control layer: policies, identity, governance, approvals, guardrails
- Execution layer: compute, networking, CI/CD, environments
- Telemetry layer: observability, audit trails, cost visibility
These four layers describe the system's shape: experience for developers, control for governance, execution for delivery, and telemetry for learning and accountability. The next step is to translate that model into concrete building blocks you actually have to implement to make the platform usable.
Core Components of an IDP
Below is the production minimum set. “Minimum” doesn’t mean “simple.” It means “the smallest set of capabilities that creates a repeatable, supported delivery path.”
1. Infrastructure Orchestration
The platform’s job is not to hide infrastructure; it’s to turn it into a dependable, self-service substrate. You need a consistent execution layer and a consistent way to create environments without hand-crafted exceptions.
What it typically includes:
- Compute substrate: Kubernetes (most common), ECS, or serverless, but with one clear “default.”
- Declarative provisioning: Terraform/Pulumi for infra resources; Crossplane if you want Kubernetes-native resource management.
- Environment abstractions: a consistent definition of what “dev”, “staging”, “prod”, and “preview” mean across accounts/clusters/regions.
- Standard platform services: ingress, DNS, cert management, secrets integration, service mesh (optional), base networking.
- Resource boundaries: quotas and limits by environment/team, plus standard labeling/tagging.
- Environment lifecycle: create, update, rotate, and destroy environments predictably.
Why it matters: This is what eliminates “pet environments” and the endless “works in staging” class of problems. When environments are consistent and self-service, teams can ship without waiting on infrastructure and platform-wide changes stop turning into quarter-long migrations.
2. CI/CD and Delivery Orchestration
CI/CD in an IDP is not “a pipeline template.” It’s a standardized delivery mechanism that encodes quality and governance into the release flow.
What it typically includes:
- Reusable pipeline building blocks for service types (API/worker/job/ML inference)
- Quality gates: tests, code coverage thresholds (if used), build reproducibility
- Security gates: SAST, dependency scanning, container scanning, IaC scanning
- Artifact management: versioned images/packages with provenance metadata
- Deployment strategies: canary, blue/green, progressive delivery options tied to risk tier
- Rollback story: automated rollback triggers + documented manual fallback
- GitOps or declarative env management: desired state in Git, automated reconciliation, auditable changes
- Promotion model: how code moves from dev to stage and prod, who can promote, and what checks are required
Why it matters: Standard delivery orchestration reduces variability. It also shifts governance left: instead of late-stage reviews and exceptions, quality and security become default properties of every release.
3. Service/Software Catalog
The catalog is the “system of record” for what exists in production. Without it, you can’t scale governance, incident response, cost allocation, or platform adoption.
What it typically includes:
- Service registry: service name, repo, owner, runtime, environments
- Operational metadata: on-call rotation, SLO/SLA, criticality tier
- Dependency mapping: upstream/downstream services, data stores, queues, external APIs
- Compliance posture: PII handling, data residency, encryption requirements, audit logging requirements
- Runtime posture: last deploy time, release version, health checks, alerts, and dashboards links
- AI assets (if applicable): models, endpoints, datasets (at least references), evaluation criteria, monitoring hooks
Why it matters: A catalog makes ownership and blast radius explicit, which is the foundation for both faster incident response and safer platform change. It also makes governance enforceable because policies can target “what this service is” and “what data it touches,” not just generic infrastructure rules.
4. Self-Service
Self-service is where platform value becomes real for developers. It’s not a “nice UI.” It’s the removal of tickets from the delivery path.
What it typically includes:
- Scaffolding workflows: create service from template (repo + configs + policies)
- Provisioning workflows: environments, databases, queues, caches
- Access workflows: request permissions through policy (role-based + auditable)
- Operational actions: rotate secrets, trigger deploy, roll back, view status
- Standard day-2 tasks: scaling, config changes, feature flags, preview env creation
Why it matters: Self-service is how you convert platform standards into daily developer speed. When routine actions are automated and policy-backed, teams stop queueing behind SRE/infra, and the platform team stops being a manual fulfillment layer.
5. Observability and Operational Tooling
Observability in an IDP isn’t about having monitoring tools installed. It’s about making observability a built-in, standardized platform capability.
What it typically includes:
- Logs/metrics/traces by default via platform-injected libraries/sidecars/agents
- Standard dashboards per service type: latency, error rate, saturation, dependencies
- Alert conventions: ownership routing, severity definitions, paging rules
- SLO tooling: error budgets, burn rates, release gating rules
- Runbook patterns: templates generated per service, linked from alerts
- Audit trails: who deployed what, which policy blocked or allowed a release, and configuration drift history
- Cost visibility hooks: tags, allocation reports, anomaly alerts (ties into governance)
Why it matters: Standard telemetry creates a shared operational language across teams, so debugging, on-call, and governance stop being bespoke per service. It also closes the control loop for leadership: you can tie changes to reliability outcomes and cost signals, not just “green builds.”
The next step is making sure teams can repeat the safe path without reinventing it. That repeatability is exactly what golden paths deliver.
Golden paths: paved, opinionated, supported
Golden paths are pre-designed, supported workflows for the most common and most important engineering scenarios.
Key properties:
- Opinionated: one recommended path reduces decision fatigue and prevents accidental complexity.
- Supported: the platform team maintains it, monitors it, and evolves it — teams aren’t stuck on abandoned templates.
- Integrated: the path includes everything: repository scaffolding, CI/CD, security checks, observability, rollout strategies.
Example: a golden path for a new web service might create a repo from a template, provision dev/stage environments, connect SAST/DAST, set up dashboards, and enable safe rollout in minutes.
Golden paths do more than standardize delivery. They shape behavior. When the paved path is the fastest, most teams will follow it. Still, production cannot depend on good intentions alone. Edge cases, urgent fixes, and one-off needs will happen. The platform needs clear boundaries for what must never happen.
Guardrails: curbs, not walls
Golden paths are how you make the recommended way fast. Guardrails are how you make the unsafe way difficult, without turning the platform into a gatekeeping bureaucracy.
The key distinction is intent:
- Golden paths optimize for flow: low-friction, high-frequency work.
- Guardrails optimize for integrity: prevent rare but costly mistakes.
A mature IDP uses guardrails to protect a small set of non-negotiable invariants: security posture, compliance controls, and unit economics. Everything else should stay flexible.
What makes a guardrail “platform-grade”? A guardrail is platform-grade if it’s:
- Automated – enforced by policy-as-code or pipeline controls, not human checklists.
- Transparent – developers can see what failed and how to fix it.
- Risk-based – stricter for higher-criticality services and regulated data.
- Rarely disruptive – high-friction interventions should be uncommon events, not daily blockers.
- Paired with a paved alternative – if you block something, you must provide a safe, supported path that works.
If a guardrail blocks routine delivery, teams will route around it (shadow tooling, manual deploys, “temporary” exceptions that become permanent).
Guardrails protect platform integrity, but they don’t create velocity by themselves. Velocity comes from how often teams can ship safely without thinking about infrastructure. That’s why golden paths and guardrails must ship together: one makes the right thing easy, the other makes the wrong thing hard.
Building Security and Governance Into the Platform DNA
Golden paths and guardrails make delivery repeatable, but repeatability alone doesn’t guarantee safety. As soon as your platform becomes the default route to production, it also becomes the default route to risk—unless security and governance are designed as native platform capabilities, not external checkpoints.
That’s the core shift in cloud platform engineering: governance stops being a “lane” outside delivery and becomes part of the delivery system itself. Instead of relying on manual review, tribal knowledge, or late-stage approvals, the platform encodes standards as automation, and it produces evidence that teams and auditors can trust. This is how control becomes a default property of the delivery system, not a series of manual gates.
Governance as Code: Policies That Ship Like Software
To make governance scalable, you need it to behave like software: versioned, testable, and continuously improved. Otherwise, policies degrade into PDFs and “best practices,” and teams inevitably route around them.
In a production-grade internal developer platform architecture, this means policy moves closer to where work happens:
- Policy-as-code for infrastructure and runtime (network, encryption, data handling, workload constraints).
- Policy bundles based on service criticality (Tier 0 vs Tier 3 is not a label–it changes enforcement).
- Policy testing in CI, so changes are predictable and reviewable.
- A strict exception flow: explicit, time-bound, traceable.
Once policies are coded, the platform can enforce them consistently. But enforcement only works when the platform also controls who can do what—across the portal, CI/CD, cloud accounts, and runtime environments. That’s why identity and access must be designed as a first-class platform capability, not stitched together tool by tool.
Identity and Access: The Platform Must be The Source of Truth
Governance breaks at scale when identity is fragmented. If your portal, CI/CD, cloud accounts, and clusters each have their own access model, you’ll never achieve consistent control—only patches and exceptions.
That’s why mature platform engineering solutions treat identity as a first-class platform concern:
- SSO + RBAC/ABAC across platform interfaces and execution layers.
- Least privilege by default, tied to catalog ownership.
- Just-in-time production access with expiry and full audit logging.
- Separation of duties for high-risk actions (IAM, keys, data export).
At this point, access is controlled and auditable—so ownership and accountability are clear. What still needs to be made equally reliable is the artifact itself: what exactly gets built, what it contains, and what reaches production. That’s when supply chain security shifts from a best practice to a built-in platform capability.
Supply Chain Security: Prove What You Ship
In cloud-native systems, the most expensive failures rarely come from “bad code.” They come from compromised dependencies, untracked images, or uncontrolled build systems. Therefore, artifact integrity must be a standard platform capability rather than a special-case control.
That’s why supply chain security becomes the next layer of platform governance:
- Signed artifacts and provenance metadata (commit → build → image/package).
- Dependency, container, and IaC scanning as standard pipeline gates.
- SBOM generation and retention for audit and incident response.
- Deployment policies that can reference provenance (“only trusted, signed artifacts deploy to prod”).
Once you can prove what you ship, you can also stop arguing about “why cloud spend grew”, because cost becomes observable and governable, like reliability.
Cost Governance: Guardrails for Unit Economics, Not Just Budgets
Cost control fails when it’s treated as finance reporting. By the time you see a monthly bill, engineering decisions have already happened—at the service level, environment level, and architecture level.
A digital platform engineering approach flips this: cost becomes an engineering signal, and good economics becomes the default path.
Enforced tagging/labels and ownership-based allocation (from the catalog).
- Quotas and limits by environment/team, aligned with service criticality.
- Cost per service and per environment is visible in the platform experience layer.
- Defaults that are cost-aware (right-sized templates, sane autoscaling, safe storage classes).
Now you have enforcement (policy), control (identity), integrity (supply chain), and economics (cost). But leadership and compliance still need one more thing: evidence.
The Trust Loop: Evidence for Auditors and Leaders
This is the 'closing of the loop' that separates real platform engineering from a one‑off tooling initiative. A governance-enabled IDP can answer, without heroics:
- Who deployed what, when, and why?
- Which policy allowed or blocked the change?
- What configuration drift occurred, and when?
- What was the impact on SLOs and cost signals?
When the platform can consistently produce these answers, governance stops being friction. It becomes a reliability and trust multiplier, which is exactly the promise of platform engineering in regulated domains and AI-heavy systems.
When governance is implemented as defaults and evidence, it stops being a brake on delivery. But it still has to become the way teams actually ship. That’s why the rollout should start with a small, complete MVP: one paved path that is faster than the alternatives and safe by construction.
From Zero to MVP: A Practical Implementation Roadmap
The most common mistake is treating the IDP as a big-bang build. But an internal platform is a product, and products win by delivering value early and expanding based on usage.
So the most practical answer to how to build an internal developer platform is: ship one end-to-end golden path, prove it, then multiply it.
Phase 0 (2-4 weeks): Alignment and Constraints
Before building, you need a tight scope and measurable outcomes. Otherwise, “platform” becomes a bucket for everything infrastructure-related.
In this phase, the output is a short platform charter:
- Who is your customer (which teams, which workloads)?
- What service type is first (web service, worker, job, ML endpoint)?
- What are the non-negotiables (security posture, env model, ownership rules)?
- What’s the primary interface (portal vs CLI)?
Most importantly, define success metrics upfront: lead time, onboarding time, deployment frequency, and incident rate. These become your baseline for deciding when to adopt platform engineering as a strategic investment, not just a tooling upgrade.
Now you’re ready for the MVP: one workflow that removes tickets and reduces cognitive load.
Phase 1 (4-8 weeks): MVP Golden Path
The MVP is not a portal. It’s a repeatable, supported delivery loop:
- Scaffold a service (repo, baseline configs, and policies).
- Build, scan, and publish an artifact with provenance.
- Deploy to dev/stage consistently (GitOps or equivalent).
- Observability defaults: dashboards, alert routing, and runbook link.
- Register in the catalog with owner/on-call/criticality.
This is where adoption starts: teams don’t adopt “platform strategy,” they adopt time saved. If the golden path makes shipping materially easier, the platform earns permission to add stronger guardrails without becoming a blocker.
Phase 2 (6-12 Weeks): Guardrails and Day-2 Operations
Once teams run real workloads through the platform, the next bottleneck is day-2 operations. If routine actions still require SRE tickets, you’ll recreate the queue you tried to remove.
So Phase 2 expands the platform’s operational surface:
- Admission policies for runtime and network constraints.
- Self-service rollbacks, secret rotation, and preview environments.
- Progressive delivery tied to criticality (canary for Tier 0).
- Exception workflow with expiry.
By the end of this phase, the platform is no longer “how to deploy.” It becomes “how to operate safely at scale.”
Phase 3 (Ongoing): Expand Service Types and Reduce Variance
Now you can scale the platform by multiplying paved paths:
- Add more service archetypes (workers, data pipelines, ML inference).
- Normalize observability and governance across all types.
- Make org-wide changes safe (base image upgrades, policy changes, runtime upgrades), because the platform can roll out changes predictably.
At this stage, platform engineering becomes the default operating model. That’s typically the point where orgs feel the strongest ROI from platform engineering solutions, because migrations stop being quarter-long coordination exercises.
Once the platform works end-to-end, the bottleneck shifts from engineering to behavior. Consistent usage, steady improvement, and clear proof of impact become the difference between a platform that scales delivery and a platform that remains “optional tooling.”
Adoption, Metrics, and the Product Mindset
Even the best internal developer platform architecture can fail if it’s treated as “enablement tooling.” Teams won’t adopt it because leadership says so. They adopt it because it’s clearly better than alternatives—and because it keeps getting better.
That’s why platform engineering needs a product mindset: explicit customers, roadmap, support, and measurable outcomes.
Treat Platform Engineering as a Product
This isn’t about branding. It’s about operating the platform like a service with accountability:
- Customer segments (new teams vs mature teams; regulated vs non-regulated).
- Roadmap based on friction and usage, not internal preferences.
- UX and docs as first-class deliverables.
- Support model with internal SLAs.
This is what turns the platform into a dependable internal product that teams rely on daily.
Metrics That Prove Value (and Reveal Failure)
To make adoption sustainable, metrics have to do two jobs at once. First, they must prove the platform is reducing friction for engineers (speed and cognitive load). Second, they must prove it’s increasing organizational control (reliability, security posture, and cost discipline). Track a small set consistently, baseline them before rollout, and review them like product KPIs, not like occasional ops reports.
In practice, it helps to group metrics by what you’re trying to improve and what you’re trying to protect. The categories below map to the platform’s core promises: faster delivery, safer production, lower operational drag, and provable governance.
Flow
- Lead time for change
- Deployment frequency
- Time-to-first-deploy
- Time to spin up preview environments
Reliability
- Change failure rate
- MTTR
- SLO compliance/error budget burn
Operational Load
- Share of senior time spent on pipelines/IAM/env troubleshooting
- Platform-related tickets per team per sprint
Governance Evidence
- Policy violations caught pre-prod
- Time-to-remediate critical vulnerabilities
- Coverage of signed artifacts / SBOM across services
If these numbers don’t move, the platform isn’t a platform—it’s a new layer of complexity. But even strong metrics won’t matter if usage stays optional or inconsistent. The next step is making adoption repeatable, so teams default to the paved paths instead of rebuilding their own.
Adoption Strategy That Actually Works
Adoption is a rollout strategy, not a launch:
- Start with a team that feels pain and can become a reference case.
- Make the golden path the easiest path (visible time savings).
- Keep escape hatches, but make them explicit (time-bound exceptions).
- Build a community loop: office hours, feedback channel, changelog.
This is how you turn a platform from “initiative” into an internal standard and how you make the decision of when to use platform engineering feel obvious rather than ideological.
Partnering on Platform Engineering Execution
Unique Technologies helps engineering leaders turn platform engineering from an initiative into a production system. We design and implement internal developer platform architecture with measurable outcomes: faster delivery, lower operational load, and governance that scales with cloud-native and AI workloads.
Our approach combines practical cloud platform engineering foundations (standardized environments, CI/CD orchestration, observability-by-default) with platform-grade controls: policy-as-code, supply chain integrity, and cost guardrails tied to service ownership. The result is a platform that teams adopt because it removes friction—while leadership keeps clear visibility into security posture, reliability, and unit economics.
If you’re evaluating when to adopt platform engineering, or you already have platform building blocks but struggle with adoption and consistency, Unique Technologies can help you define the roadmap, ship an MVP golden path, and scale platform engineering solutions as an internal product without turning governance into bureaucracy.