
Event-Driven Architecture and Serverless: Rethinking the Backend for High-Load Systems
High-load backend systems rarely fail because one service is poorly written in isolation. More often, they begin to lose stability because too many services are forced to respond, coordinate, and complete work at the same time. A synchronous architecture can perform well for a long time, especially when traffic is predictable and service dependencies are limited. But as throughput grows, integrations multiply, and latency budgets tighten, the same architecture can become fragile in ways that are difficult to see early.
This is where many teams begin to reconsider the backend not as a chain of request-response calls, but as a system of events, independent reactions, and selectively allocated compute. Event-driven architecture can reduce direct coupling between services, absorb bursts more gracefully, and support a more scalable processing model. Serverless models can extend that flexibility by allowing teams to execute code only when events or requests actually occur, rather than keeping infrastructure running for peak conditions at all times.
That does not mean these approaches are automatically the right answer. Event-driven systems introduce new forms of complexity around contracts, observability, retries, and consistency. Serverless computing architecture can remove infrastructure overhead in one part of the system while introducing new bottlenecks or cost distortions in another. The real architectural question is not whether these models are modern. It is whether they match the operational shape of the problem.
This article examines why synchronous high-load systems become brittle under pressure, where event-driven architecture adds real value, and where it creates new trade-offs. It also explores observability in asynchronous systems, the practical limits of serverless functions, and how these choices apply in enterprise environments, including Japan. We will also explain how Unique Technologies approaches the design of high-load event-driven systems in practice.
The Core Problem with Synchronous High-Load Systems
The core weakness of a synchronous high-load system is not simply latency. It is dependency timing. In a synchronous flow, one service depends on another service being available right now, with an acceptable response time, under the current load, and without failure. One slow downstream system can hold threads, connections, memory, retries, and user-facing requests hostage across the stack. Under real pressure, this turns architecture into a traffic coordination problem, not just an application problem.
This creates several structural limitations:
- Tight temporal coupling. Even when services are logically separate, they are still operationally tied to each other’s response times.
- Failure amplification. A local slowdown can cascade into queueing, timeout storms, retry floods, and degraded user experience upstream.
- Poor spike tolerance. Sudden traffic increases can overwhelm dependencies faster than autoscaling or caching strategies can compensate.
- Inefficient resource use. Systems are often provisioned for worst-case synchronous demand, even though much of the work does not need to happen in-line.
This is why many high-load systems become increasingly difficult to evolve. Teams keep improving components, but the architecture still assumes that every meaningful action must happen immediately and in order.
In practice, much of that work does not belong in the critical path at all. Notifications, audit logging, search indexing, analytics ingestion, downstream synchronization, enrichment, and many background workflows can often be processed asynchronously. Once teams clearly recognize that distinction, the backend can be redesigned around what truly needs immediate consistency and what does not.
That shift is often the first real step toward architectural scalability.
Event-Driven Architecture: Principles, Patterns, and When It Backfires
Event-driven architecture changes the communication model of the backend. Instead of forcing services to call each other directly for every step of a business process, one part of the system emits an event when something meaningful happens, and other parts react to it independently.
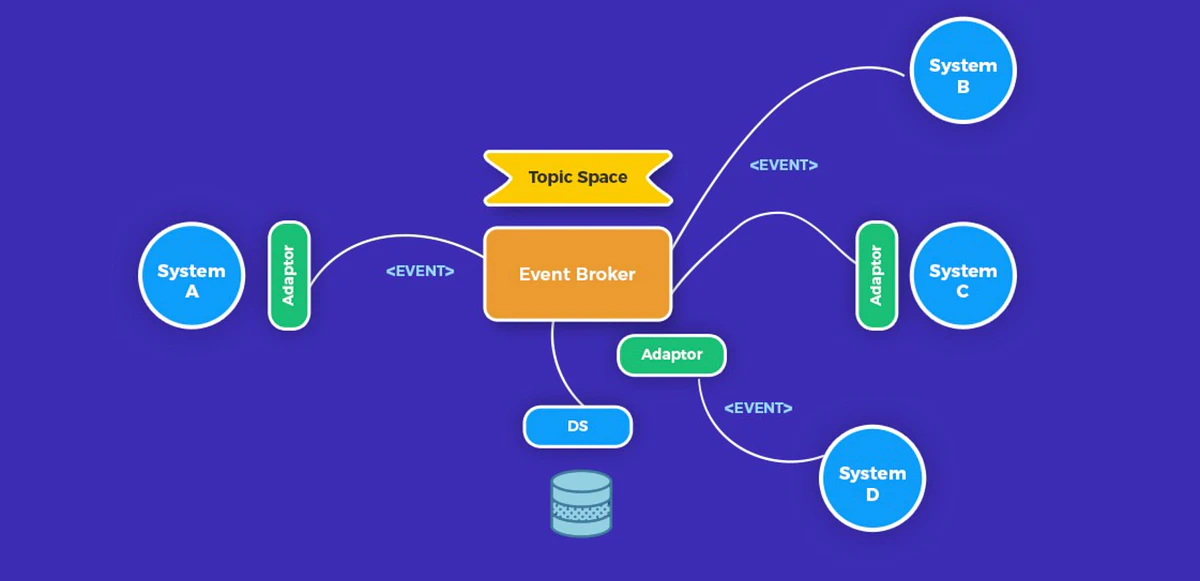
In practice, the benefits of event-driven architecture only emerge when the events represent real domain behavior, and the system is designed around disciplined contracts rather than informal notifications.
At a high level, the most useful event-driven architecture patterns for high-load systems include:
- Event notification. A service announces that something has changed, and consumers decide what to do next.
- Event-carried state transfer. The event includes the data consumers need, reducing follow-up reads and lowering pressure on the source service.
- Pub/sub fan-out. One event triggers multiple downstream actions, such as analytics, notifications, billing updates, or compliance workflows.
- Transactional outbox. State changes and outgoing events are persisted together so that the system does not silently lose important messages.
- Saga-based workflows. Distributed business processes are modeled as a sequence of steps with compensation logic when one stage fails.
These patterns are especially useful when a system needs to do one or more of the following:
- Absorb irregular traffic
- Distribute work across independent consumers
- Isolate side effects from the customer-facing request path
- Integrate legacy and modern services without deep point-to-point dependencies
- Process naturally asynchronous domain workflows
This is where the benefits of event-driven architecture become concrete. Teams usually gain:
- Better resilience under bursty load
- Clearer workload separation
- More flexible scaling
- Reduced coupling between producers and consumers
- A more practical way to integrate multiple internal and external systems
But event-driven architecture also backfires in predictable ways.
It usually goes wrong when teams:
- Publish unstable event payloads and treat them as implementation details rather than durable contracts
- Introduce asynchronous messaging, where simple synchronous calls would have been easier and safer
- Rely on choreography everywhere, even for workflows that need explicit control and accountability
- Ignore duplicate delivery, retries, idempotency, and dead-letter handling
- Mistake “loosely coupled” for “easy to reason about”
This is the point many teams discover too late: EDA does not remove complexity. It redistributes it.
A well-designed event-driven system can be easier to scale. The most common failure mode is teams that adopted EDA for scalability, then spent six months debugging a business process spread across eight queues with no correlation IDs, no dead-letter visibility, and no way to tell operations where an order actually was.
Observability Challenges in Event-Driven Systems
The moment a system becomes asynchronous, observability stops being a service-level exercise and becomes a flow-level discipline.
In a synchronous architecture, engineers can usually trace one request through a bounded execution path. In event-driven systems, that same business action may become a series of messages, retries, delayed consumers, parallel handlers, and downstream effects that happen at different times in different places.
This creates a visibility problem that many teams underestimate.
The questions that matter in production are no longer only technical questions, such as whether a consumer is healthy or whether a queue is reachable. They become operational business questions:
- Where is this order, payment, document, or workflow right now?
- Which consumer is delaying progress?
- Is the backlog growing because of producer volume, consumer failure, or downstream slowness?
- Are retries helping the system recover, or are they amplifying instability?
- Which event version is causing breakage across services?
To answer those questions, high-load event-driven systems need more than standard logs and infrastructure dashboards. They need:
- Correlation and causation IDs carried through events
- Stable event schemas and versioning rules
- Distributed tracing across asynchronous boundaries
- Queue depth and consumer lag monitoring
- Dead-letter queue visibility
- Event age and processing latency metrics
- Business-flow dashboards, not only service dashboards
This is where many teams make a costly mistake. They build asynchronous architectures for scalability, but keep observability at the level of CPU, memory, and application logs. The result is a system that can technically process large volumes of work, but cannot explain where business work is getting stuck.
For enterprise platforms, that is not good enough. A high-load architecture must not only survive load. It must remain diagnosable under load. That is why observability in event-driven systems has to be designed as part of the architecture itself, not added later as an operational patch.
But visibility alone does not make an asynchronous system operationally sound. Once teams can see how work moves through the system, the next question becomes how that work should actually be executed under changing load. In other words, the discussion shifts from communication patterns to runtime models. This is where serverless enters the picture.
When Serverless Works, and When It Quietly Becomes Your Biggest Problem
Serverless computing architecture takes the decoupling principle one step further: instead of provisioning servers, you deploy functions that execute on demand, scale to zero when idle, and scale out automatically under load. Combined with managed event sources (queues, streams, object storage, and databases), serverless solutions can remove an entire category of infrastructure work from the platform team.
For the right workloads, that's transformative. For the wrong ones, it quietly becomes the biggest operational problem in the system.
Where Serverless Functions Shine
- Event processing at variable load. If your workload is bursty or unpredictable (webhook ingestion, image processing, stream transformations, scheduled jobs), serverless matches capacity to demand without manual scaling or idle cost.
- Glue code between managed services. Small functions that react to an object storage upload, transform the file, and write to a database are exactly what serverless is optimized for.
- Low-to-moderate throughput APIs with spiky traffic. Serverless absorbs traffic spikes without capacity planning. For backends that don't run hot 24/7, the economics and operational simplicity are hard to beat.
- Isolated workloads with clear boundaries. When a function has one job, one input source, and one output, serverless lets a single engineer own it end-to-end.
Where Serverless Quietly Becomes the Biggest Problem
- High-throughput, latency-sensitive APIs. Cold starts, concurrency limits, and per-invocation overhead add up fast. Cold starts themselves are often manageable, but the standard fix – Provisioned Concurrency – keeps a set number of function instances pre-initialized and bills for them continuously, regardless of traffic. That trades the "pay only for what you use" model for something closer to reserved capacity, which is exactly the model serverless was meant to replace. For sustained, high-throughput traffic where functions run hot 24/7, the per-invocation pricing model of serverless typically exceeds the cost of a right-sized container fleet — especially when execution times exceed a few hundred milliseconds or warm caches materially reduce latency.
- Long-running workloads. Most serverless platforms cap execution time. If your job routinely runs longer than that, you'll rearchitect around the limit instead of solving the actual problem.
- Workloads with heavy local state or warm caches. Every cold start is a fresh environment. Functions that benefit from in-memory caches, loaded ML models, or persistent connections pay a tax on every invocation.
- Deep integration with traditional databases. Connection pooling is a known pain point. Hundreds of concurrent function instances opening connections to a relational database will exhaust the pool long before they exhaust the function platform.
- Complex local development and testing. Serverless platforms differ meaningfully across clouds. Local parity is limited, integration tests are harder, and "it works in the console" is not a reliable signal. The failure mode is consistent: teams adopt serverless because it promises to eliminate infrastructure work, then spend months working around its constraints in ways that cost more than the infrastructure would have. Serverless is a specialized tool that pays off when the workload matches the model, and a poor fit when it doesn't.
That framing matters because the most powerful use case for serverless isn't "run an API on it." It's combining it with event-driven architecture for workloads where elastic, asynchronous execution is exactly what the system needs.
EDA + Serverless Together: Architecture Patterns for High-Load Systems
The most effective systems often combine event-driven architecture with selective serverless usage, rather than treating them as the same thing.
EDA defines how parts of the system communicate. Serverless defines one way to execute some of that work. When used together carefully, they can create architectures that are both scalable and operationally efficient.
Several patterns work especially well in high-load systems.
1. Asynchronous Ingress
A request enters the system, basic validation happens immediately, and the core intent is recorded. Everything that does not need to happen synchronously is emitted as an event and processed downstream.
This pattern is useful when:
- The user-facing flow should stay fast
- Downstream actions are variable in duration
- Third-party dependencies are unreliable
- One action needs to trigger multiple follow-up steps
2. Outbox Plus Fan-Out Consumers
A service persists a business change and records an outgoing event in the same transaction. That event is then published and consumed independently by other parts of the platform.
This works well for:
- Order processing
- Billing events
- Notification systems
- Audit and compliance pipelines
- Search and analytics updates
3. Orchestrated Cross-Service Workflows
Some workflows are too important to leave entirely to implicit choreography. In those cases, a coordinator or workflow engine provides a clearer operational model.
This is often the better choice when:
- Multiple services must complete a single business process
- Compensating actions are required
- The workflow state must be visible to operators
- Teams need clearer governance and auditability
4. Serverless at the Edge, Durable Services at the Core
This is often the most practical pattern for enterprise systems.
Use serverless functions for:
- Inbound events
- External integrations
- File-triggered processing
- Traffic bursts
- Lightweight transformations
Use durable services or containers for:
- Stateful business logic
- Long-running tasks
- Latency-sensitive APIs
- Complex workflow coordination
- Core domain processing
This hybrid model gives teams many of the benefits associated with event-driven architecture and serverless solutions, without forcing the entire platform into one operational style.
That balance is often what separates scalable systems from architectures driven more by trend than by operational fit. This distinction becomes especially important in the Japanese enterprise context, where architecture decisions are shaped not only by performance goals, but also by requirements for predictability, maintainability, and controlled modernization.
Applying EDA in the Japanese Enterprise Context
Japanese enterprises approaching 2025-2026 face an unusual combination of constraints. Many are modernizing systems that have been running in production for fifteen to twenty years, often within environments shaped by long-lived vendor relationships, strict operational expectations, and a strong need for auditability, predictability, and interoperability. At the same time, consumer-facing products such as mobile applications, real-time digital services, and AI-powered features demand a level of elasticity and responsiveness that many legacy backends were never designed to support.
This tension is one reason event-driven architecture fits Japanese enterprise reality more naturally than it may first appear. METI’s recent framing of legacy modernization reflects the broader pressure to move away from rigid, aging system estates toward architectures that can support continuous business change. In parallel, Japan’s Digital Agency has been emphasizing interoperability, common rules, and structured data exchange across systems. Taken together, these priorities favor explicit contracts, traceable system behavior, and manageable integration models over opaque point-to-point coupling.
In practice, EDA is often most effective in this environment not as an all-or-nothing architecture style, but as a boundary strategy for controlled modernization. It is especially valuable at the seams between legacy cores and new digital channels, between systems owned by different vendors, and between core transaction platforms and downstream analytics, notification, or compliance workloads.
Several qualities make this approach particularly relevant in Japan:
1. Auditability Is a Native Property of Event Streams
Regulated industries in Japan (finance, healthcare, insurance, telecom) require traceable records of state changes. An event-sourced or event-logged system produces exactly that kind of record as a byproduct of how it operates. Every state transition is a durable, timestamped, replayable event. For organizations where "who changed what, when, and why" is a compliance requirement, EDA is less a new pattern and more a formalization of existing expectations.
2. Gradual Modernization Without Rewrite Risk
Japanese enterprises typically cannot afford big-bang migrations. Event-driven patterns support a strangler-style modernization: legacy systems continue to handle synchronous transactions, while events published from those systems feed new capabilities (AI inference, real-time analytics, mobile features) without requiring the legacy core to change. The old system keeps running; the new system evolves alongside it.
3. Resilience Aligned With Operational Culture
Japanese engineering culture values predictable operations and clear escalation paths. EDA, done well, produces exactly that: failures are isolated to individual consumers, retries are explicit, dead letter queues are visible, and recovery procedures are codified. It's the opposite of the "mysterious outage" pattern that teaches organizations to distrust distributed systems.
4. Serverless as a Hedge Against Operational Overload
For Japanese enterprises with constrained engineering headcount (a reality for many mid-sized corporations), serverless solutions offload an entire class of operational work to the cloud provider. Scaling, patching, capacity planning, and idle resource management stop being internal concerns. That matters enormously when the engineering team is small relative to the system's ambition.
5. Interoperability Through Explicit Schema Contracts
Japan's Digital Agency framework requires systems to expose and consume data through defined, stable interfaces. EDA enforces exactly that: every event is a versioned, schema-governed contract between a producer and its consumers. An event-driven architecture with a schema registry is not just a scalability choice — it is a structural fit for interoperability requirements. Systems that exchange events through stable schemas can be integrated, audited, and replaced independently, without rewriting the interfaces between them.
The caveat is that EDA and serverless both require discipline at adoption time. Schema management, observability, and clear event ownership have to be set up before scale arrives, not after. Japanese enterprises tend to do this well when the architectural choice is made deliberately; they tend to struggle when EDA is adopted in imitation of foreign reference architectures without the operational foundation in place.
How Unique Technologies Builds Event-Driven Systems
At Unique Technologies, we help engineering leaders design and operate backend systems where event-driven and serverless computing architectures deliver measurable outcomes in production. Our work centers on three principles.
1. Architecture Decisions Are Constraint-Driven, Not Fashion-Driven
We start every engagement by mapping the actual workload: throughput patterns, latency requirements, failure modes, team maturity, and compliance constraints. Event-driven architecture patterns are introduced, where they solve a specific problem: fan-out load, resilience under downstream failure, auditability, and elastic scaling of asynchronous work. In practice, roughly half of the integrations we review don't need a message broker — they need a better synchronous design with circuit breakers and proper timeout handling. The other half are genuinely bottlenecked by synchronous coupling and benefit immediately from event-driven patterns. Knowing which is which before committing to an architecture is where most of the value sits. The goal is fit, not pattern adherence.
2. Observability and Governance Are Designed In From the Start
We treat schema registries, correlation IDs, distributed tracing, dead letter queue ownership, and business-level dashboards as day-one deliverables. Teams that inherit our systems can debug them under pressure because the observability layer was never an afterthought. For serverless solutions, we build local-development parity, integration testing, and cost visibility into the platform before production traffic arrives.
3. Migrations Happen Without Business Interruption
Most of our enterprise clients are evolving existing systems rather than building greenfield ones. We use strangler patterns, dual-write transitions, and event-log bridges to introduce EDA and serverless functions alongside legacy systems, rather than replacing them wholesale. The legacy core keeps running while new capabilities come online. Rollback is always possible because the old path is never removed until the new path is proven.
Unique Technologies helps teams make that distinction in practical terms. We design and evolve high-load systems with the architecture, observability, and integration strategy needed to scale safely. If you're evaluating whether event-driven architecture or serverless computing architecture is the right answer for your high-load backend, or if you've already started and need a partner who has built these systems in production before, Unique Technologies can help you make that decision with rigor and execute it without disrupting the business.