
The Role of Human‑in‑the‑Loop in the Age of AI Automation
Every technological wave comes with the same promise: automate away complexity, cost, and human error. With AI automation, that promise feels closer than ever. Autonomous agents can already generate code, summarize contracts, draft marketing copy, and orchestrate workflows across tools with minimal supervision.
But as C-level management quickly discovers, scaling AI doesn’t mean removing humans from the loop. It means deciding where human judgment must remain non-negotiable, because context, accountability, and trust aren't generated by models. They are designed by humans.
The human-in-the-loop (HITL) model, where people remain embedded in training, validation, and deployment, has moved beyond being a temporary safeguard. It’s becoming a durable architectural and organizational principle for building systems that are reliable, auditable, and commercially sustainable. In other words, human-in-the-loop AI is not the opposite of automation; it’s how automation survives real-world constraints.
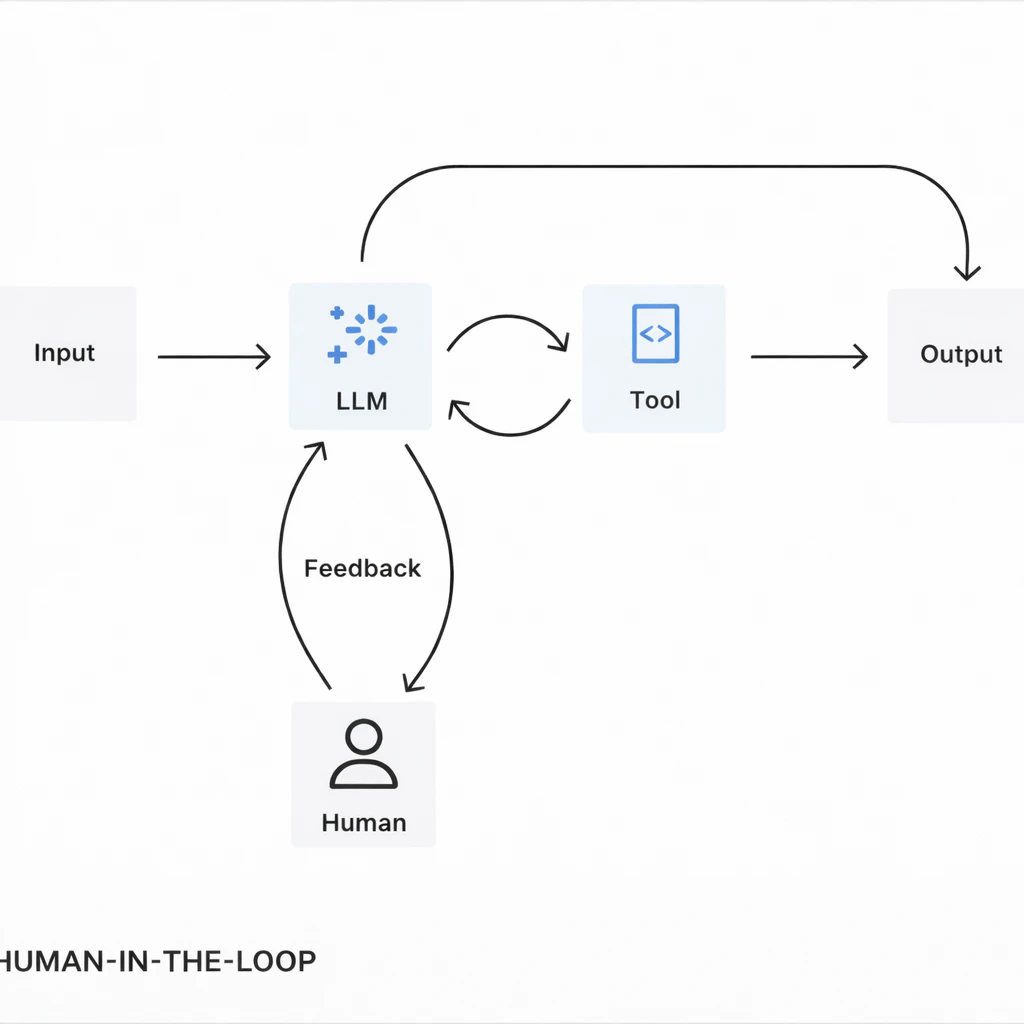
To illustrate this in practice, in this article, we’ll move from strategy to implementation: how "full autonomy" assumptions break in production, what control models actually mean (HITL vs HOTL vs HIC), where HITL is essential, how to design workflows from UX to MLOps, what the economics look like, and how distributed teams operationalize this without slowing delivery.
Before we define workflows and roles, we need to align on a bigger shift: the industry is moving from automation fantasies to a more operational concept, responsible, controlled intelligence. That shift explains why HITL is not going away.
From Full Automation Dreams to Responsible AI Reality
For years, the dominant narrative around AI has been about full autonomy: self-driving operations, self-managing workflows, self-improving systems. The implicit idea was simple: once models are good enough, humans could be excluded from the process.
Reality is more complicated. Autonomy works best in environments that are stable, fully measurable, and reversible. Most business environments are the opposite: they change constantly, include incomplete information, and carry hidden costs when something goes wrong. That’s why the hard part of integrating AI into real‑world operations is rarely a model problem. It’s a governance and context problem.
A core truth emerges in production: Autonomy without context is brittle. Modern systems may look self-sufficient, but they sit on top of human decisions:
- What data is collected and how it’s labeled,
- Which outputs are acceptable (policy, legal, brand),
- What tradeoffs matter (speed vs safety, cost vs quality),
- What "good" means in a specific business setting (result, metric), not in a benchmark.
Without structured feedback, models drift. And drift doesn’t always show up as obvious failures. It often appears as:
- Subtle tone shifts that damage customer trust,
- Gradual increases in hallucinations or omissions,
- Rising policy violations hidden inside "mostly correct" outputs,
- Edge-case behavior that only surfaces at scale.
This is why responsible AI is increasingly treated as an operating model, not just a principle on paper. In practical terms, responsible AI means building systems with human oversight where impact is high and auditability when decisions need justification. It also means putting controls in place to prevent silent degradation and creating feedback loops that turn human judgment into model improvements.
In this framing, automation is the acceleration of decision-making through machine pattern recognition, while humans retain authority where it matters most.
Now that we’ve anchored the "why," the next question becomes operational: what exactly is the human contribution that AI can’t replace in business settings—and how do you structure it so it scales?
Quality, Accountability, and Trust: The Human Value Chain
In enterprise AI, "performance" isn’t just a metric on a dashboard. It’s a commitment that the system will behave predictably under pressure, explain itself when challenged, and remain aligned as the business evolves. Humans remain central to that commitment in three interconnected ways:
1. Quality
Even the best generative systems must undergo human‑led evaluation cycles. Models hallucinate facts, over‑fit to biased data, or misinterpret input intent. Human reviewers evaluate not only correctness but relevance, tone, and appropriateness, especially in high-stakes fields such as medicine, education, and finance.
2. Accountability
AI may execute decisions, but accountability remains with executive and engineering leadership. As regulators move toward transparency requirements (for example, the EU AI Act, U.S. AI Executive Order), organizations must show how human judgment remains embedded within automated processes.
3. Trust
Customers, employees, and partners need assurance that they are dealing with transparent, accountable algorithmic systems. HITL workflows provide explainability: humans can adjust outputs, review rationales, and make the system’s decision chain legible.
So the value chain is clear: humans protect quality, carry accountability, and enable trust. The next step is making this actionable: different organizations use humans in different ways, and the terminology matters because it affects architecture, staffing, and responsibility boundaries.
Human‑in‑the‑Loop vs Human‑on‑the‑Loop vs Human‑in‑Command
Human‑in‑the‑Loop (HITL), Human‑on‑the‑Loop (HOTL), and Human‑in‑Command (HIC) are terms that reflect levels of control and proximity between humans and intelligent systems. Understanding the differences helps organizations architect their governance frameworks appropriately.
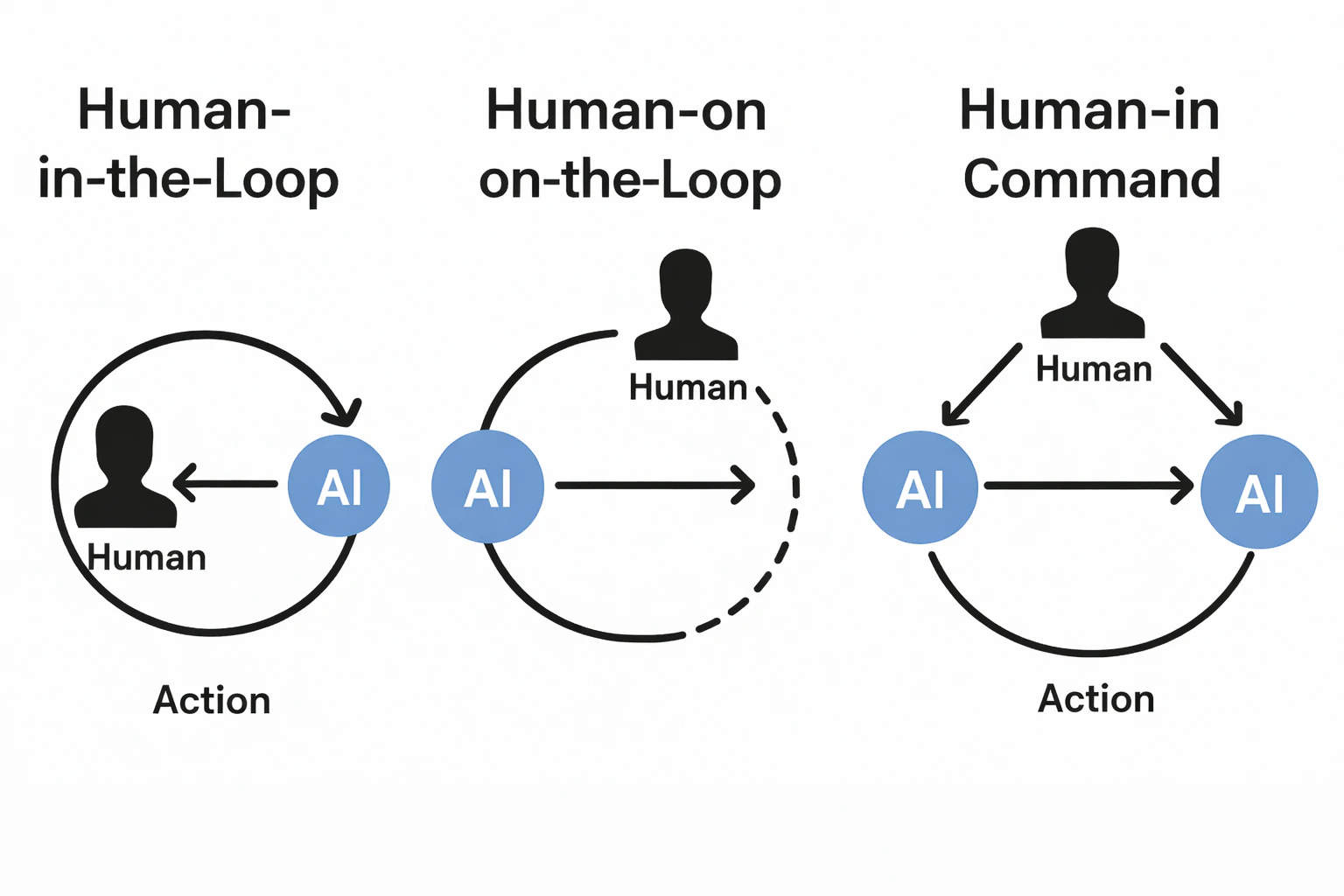
HITL
Humans actively participate before the system takes high-impact actions. This can mean approval, editing, labeling, or structured feedback.
Typical patterns:
- Approval gates for high-risk outputs
Require human sign-off before sensitive actions, such as sending customer communications, publishing legal text, or executing large financial transactions. - Mandatory review when confidence is low
When the model is uncertain, it routes the case to a human to prevent “best guess” behavior from becoming an incorrect decision. - Human verification for regulated decisions
Add explicit human confirmation for compliance-heavy domains (finance, healthcare, HR) where you need defensible decisions and clear accountability. - Human correction as a training signal
Capture edits and rejections as labeled feedback so the system improves over time instead of repeating the same failure modes.
HOTL
The system runs by default, while humans supervise and intervene through monitoring, escalation queues, and overrides.
Typical patterns:
- Alerting thresholds and anomaly detection
Trigger alerts when quality, latency, cost, or behavior deviates from expected ranges, so teams can intervene before users feel the impact. - Exception queues
Route edge cases and policy-sensitive items into a review queue, keeping the main flow automated without ignoring high-risk outliers. - Audit sampling
Regularly review a sample of outputs to detect emerging issues early, even if metrics look “fine” on the surface. - Human overrides
Provide an immediate kill switch or manual takeover path so operators can stop actions, correct outcomes, or revert behavior quickly.
HIC
Humans define objectives, constraints, and escalation rules at the policy level. AI operates inside those boundaries. Humans retain ultimate authority and accountability.
Typical patterns:
- Policy-defined boundaries and permitted actions
Specify what the AI is allowed to do (and not do), including limits by role, data sensitivity, and operational context. - Audit logs and approvals for boundary changes
Treat policy changes like production changes: versioned, approved, traceable, and reviewable for governance and incident investigations. - Escalation playbooks
Predefine what happens when rules are hit: who gets notified, what actions are paused, and how exceptions are handled consistently. - Role-based authority
Ensure only authorized roles can approve risky actions or modify boundaries, keeping accountability clear and reducing insider risk.
Here is a table that breaks down the most significant factors to consider when choosing the right model for your organization:
MODEL | DEFINITION | INDUSTRY EXAMPLE | RISK LEVEL |
Human‑in‑the‑Loop (HITL) | Humans directly participate in data labeling, decision validation, or feedback loops. | RLHF training on chat models; content review pipelines. | Low risk if workflows are well‑defined. |
Human‑on‑the‑Loop (HOTL) | Systems operate autonomously, but humans monitor performance and can intervene. | Fraud detection models with human analysts on standby. | Moderate; depends on intervention timeliness. |
Human‑in‑Command (HIC) | Humans set system objectives, ethical boundaries, and escalation paths at a policy level. | AI use in defense applications or financial risk modeling. | Low, given strategic oversight mechanisms. |
If your team is debating what to choose, Human-in-the-loop vs. Human-on-the-loop vs.Human‑in‑Command, the simplest decision test is:
- Choose HITL when mistakes are expensive and hard to reverse.
- Choose HOTL when you can run autonomously but must detect issues fast.
- Choose HIC when the core requirement is governance: intent, constraints, and auditability.
Most mature systems layer all three: HITL for critical decisions, HOTL for monitoring at scale, and HIC for policy and accountability.
Now that the control models are clear, the next question becomes concrete: where is HITL truly essential rather than becoming an expensive ceremony?
Key Use Cases Where HITL Is Essential
HITL is not needed everywhere. It’s essential when the cost of failure is high, when the problem is inherently ambiguous, or when stakeholders require transparency. Here are the most common cases where HITL creates real value:
1. Model Training and Reinforcement Learning
Every stage of model training benefits from human feedback, from annotating raw data to fine‑tuning output preferences. RLHF has become a gold standard for aligning large language models with human intent. The human‑in‑the‑loop machine learning pipeline ensures models don’t merely optimize statistical accuracy but reflect human values.
2. Generative AI Content Evaluation
Enterprises deploying generative AI at scale (marketing, design, support chatbots) require human reviewers to assess factuality, cultural sensitivity, and tone. Without this layer, automated content risks damaging brand reputation or violating compliance norms.
3. Regulated Industries
Healthcare, finance, and legal technology rely on human validation for every AI inference that affects outcomes or compliance. "AI + clinician" is not a stopgap; it’s the only safe deployment model.
4. Safety and Risk Mitigation
Self‑driving systems, automated trading, or defense algorithms must have human intervention capabilities, not as a manual override but as a structural safety layer. Here, human‑in‑the‑loop automation ensures ethical and contextual correction under unpredictable environments.
5. AI Evaluation Services
An emerging B2B ecosystem of companies offering human‑in‑the‑loop evaluation services (Scale AI, Surge AI, Toloka, Remotasks) integrates scalable human oversight into model testing and retraining pipelines. This outsourcing trend demonstrates that HITL itself is forming an economy within the AI value chain.
Once you agree HITL is needed in specific domains, the real challenge begins: designing workflows so humans contribute targeted expertise without slowing delivery. That takes intentional design from UX all the way into MLOps.
Designing HITL Workflows: From UX to MLOps
In many organizations, human review starts as an informal QA step around AI systems. In mature systems, the HITL layer becomes an important part of the architecture. Designing it requires cross‑disciplinary thinking – product design, operations, and machine learning engineering must converge. Here are the main steps.
- Process Design. Define decision points where human feedback adds measurable value, not bureaucracy.
- Interface Design. Create intuitive annotation and review UIs — think of the UX as an "API for human judgment."
- Data Loop Integration. Use active learning to prioritize samples where model uncertainty is high, so humans focus only on edge cases.
- Feedback Instrumentation. Log, quantify, and route human interactions back into retraining datasets within your MLOps cycle.
- Measurement Framework. Track cost per intervention, retraining uplift, and accuracy improvement to evaluate ROI.
Several MLOps platforms, such as Labelbox, Snorkel Flow, or Amazon SageMaker, are already embedding these capabilities, turning the design of human feedback loops into standardized infrastructure.
Now that the workflow mechanics are clear, leadership will ask the next inevitable question: what does this cost, and how do we justify it without turning HITL into an endless operational burden?
The Economics of Human‑in‑the‑Loop
From a CFO’s perspective, additional human review looks like friction that gets in the way of cleaner, more predictable cost structures. But once failure costs are modeled as risk exposure, the trade-off shifts. Here are the core drivers that make HITL a risk-reducing investment, not just an added operating cost:
Error Mitigation. A single misclassified transaction or unsafe model output can cost millions in legal and reputational damage. Human review reduces this risk by orders of magnitude.
Knowledge Transfer. Human feedback acts as implicit transfer learning — codifying tacit organizational knowledge into machine‑readable patterns.
Scalable Learning. As models stabilize, the proportion of human interventions declines, but their impact per instance increases.
Ethical and Regulatory Cost Avoidance. HITL ensures compliance with emerging legal frameworks, mitigating penalties, and preserving market access.
To make this trade‑off more concrete, a simple decision model helps:
Expected Loss = P(error) × Cost(error)
HITL is justified when: Review Cost < Avoided Expected Loss
Viewed systemically, HITL is analogous to security testing or QA — an operational safeguard that transforms uncertainty into predictable risk management. That's why it should be treated as a strategic investment in your organization’s resilience and safety.
Now we move to the operational reality: most teams deploying AI are distributed, multi-timezone, and cross-functional. HITL can either become a coordination nightmare or a high-leverage system if implemented correctly.
Implementing HITL Across Distributed Engineering Teams
As engineering evolves toward decentralized, remote‑first operations, structuring effective HITL pipelines becomes an organizational challenge. Distributed human evaluators may differ in context awareness, data privacy exposure, or decision criteria. To overcome these barriers:
Standardize Task Protocols. Use structured annotation guidelines and decision taxonomies to harmonize quality.
Ensure Ethical Alignment. Develop principles around fairness, inclusivity, and data protection.
Use Instrument Collaboration. Integrate review boards or "AI quality councils" into your agile process, enabling cross‑functional oversight.
Automate Feedback Routing. Build APIs that feed human corrections automatically into retraining pipelines.
Measure Latency and Throughput. Treat human review capacity as a system resource and monitor its behavior under load conditions.
In practice, teams that integrate their human‑in‑the‑loop machine learning layers with automated logging and continuous retraining report faster improvement cycles and better cultural buy‑in from product teams.
With implementation covered, we can step back and ask a strategic question: if models are commoditizing, where does your organization’s competitive advantage come from? This is where HITL becomes more than governance, and it becomes differentiation.
A Human‑in‑the‑Loop as Strategic Differentiation
In the competitive AI era, technological advantage is undermined quickly. Open models, foundational datasets, and shared benchmarks make replication trivial. What remains defensible is how a company embeds human judgment into its AI lifecycle:
Brand Differentiation. Companies that communicate transparent, human‑guided AI earn deeper customer loyalty.
Operational Flexibility. Human reviewers can interpret edge cases faster than models, allowing domain‑specific adaptation.
Ethical Credibility. Investors and regulators reward firms that document how humans remain accountable within automated systems.
In essence, human‑in‑the‑loop AI is not a cost center — it’s a differentiator in trust, resilience, and adaptability. As AI commoditizes, culture and process become the ultimate moats.
In closing, let’s answer a simple question: what does the future look like if AI becomes more autonomous, but organizations still need context, accountability, and trust?
The Future Outlook: Human Intelligence as AI’s Operating System
The most forward‑thinking organizations now treat human judgment as a first‑class component of their AI architecture, akin to compute, storage, or model APIs. The next generation of AI development workflows will likely integrate feedback capture natively, automatically translating user corrections into retraining signals.
This vision represents not a compromise, but a synthesis: automation and autonomy built upon continuous human context. The goal is not to replace judgment, but to scale it.
As autonomous systems increasingly manage production code, marketing content, and customer interactions, human‑in‑the‑loop automation will ensure these systems remain adaptable, auditable, and human‑aligned.
The future of AI is neither fully autonomous nor manually controlled — it is co‑evolutionary. Humans will remain the ethical compass, contextual anchor, and creative force guiding machines through ambiguity.
For C-level management shaping AI roadmaps, the strategic imperative is clear: embed human judgment into every stage of your automation pipeline. This makes your organization not just technically advanced, but trustworthy, resilient, and truly intelligent.
Want to sanity-check your current setup or design a HITL layer for a new product? Contact Unique Technologies to discuss your use case and get a practical implementation roadmap.